Cette page présente une collection d'articles rédigés par les étudiants du DU IRMIA++, basés sur le séminaire interdisciplinaire.
Sommaire de la page
16/11/2023 - Visualization and algebraic geometry
This article was written by Ludovic FELDER and Ruben VELKY, based on the presentations given by Laurent BUSÉ and Jean-Michel DISCHLER on November 16th, 2023
Artists started giving their paintings an impression of 3D a couple hundred years ago, in order to make them realistic. The principle is pretty easy : combining a 2D support with colors and a perspective representation to give the illusion of a 3D scene. Computer generated images use the same principle except that the image isn’t on a canvas but on a screen. Since the first real time computers in the 1950’s, a lot of work regarding image generation has been done. One crucial invention to get realistic images is ray-tracing.
Ray-tracing is a technique used to model the transport of light through a 3D scene in order to generate a digital image. All we need are three elements : a light sources, objects and sensors. Light propagates from the source, then is reflected or absorbed by the objects before eventually reaching the sensors, that is the plane surface that generates the image. As an approximation, light behaves like rays that propagate in straight lines and carry an energy distribution for each wave length, called radiance. The interaction between light and an object is modelled using the so-called bidirectional reflection distribution function (BRDF), which contains all the information regarding the material of the object and its micro structure. To get a full image of a 3D scene, we therefore need to determine all the light rays reaching each pixel. In practice, we use a Monte-Carlo techniques to sample a few rays per pixel and compute the accumulated radiance. Unlike the direct light from the source to the sensors, the indirect light which undergoes several reflections before reaching the pixels is quite computationally demanding and the results may be quite noisy.
</em>")
Figure 1. Images generated by metropolis light transport (Source: [1])
Many techniques have been developed to generate better images in shorter time. For instance, as many rays actually carry a low level of radiance, importance sampling is used to select the rays directions according to the radiance distribution. This can be done adaptively based on the radiances previously calculated. One key point in the ray tracing algorithms concerns the intersection computation between the rays and the objects. To speed up the computations, the objects can be enclosed into bounding volumes to quickly check whether the rays reach the object or not.
We are now going to introduce more specific techniques for problems involving the intersection between a ray and the surface of an object or, more generally, between two objects. Here we are particularly interested in the case where the surface of the object is parameterized by rational fractions, that are fractions between two polynomials. Indeed, we will see how algebraic geometry tools can be used to tackle intersection problems and solve real-life problems, like manufacturing objects of a given shape.

Figure 2. Intersection problem
Suppose that the contour of a two-dimensional object is represented by two parametrized curves, finding the intersection points of these two curves can be a crucial step in programming the milling machine that will carve the object. The method used to find their intersection points relies on the Sylvester resultant, which is the determinant of a matrix in the coefficients of the rational fractions defining a parametrized curve. The Sylvester resultant provides an implicit equation for one curve. After inserting the parametrization of the second curve into this implicit equation, we get a polynomial equation to find out the intersection points. The whole problem can actually be reformulated as a generalized eigenvalue problem and therefore efficient numerical linear algebra methods can be used to make the computations.
The extension to the intersection between a curve and a surface is more intricate. One difficulty comes from the base points of the surface, which are points for which the parameterization is not well defined projectively. To overcome this difficulty, instead of resultant-based methods, a non square matrix, called matrix of syzygies, is considered : its rank drops out exactly on the surface. Then plugging the parameterization of the curve gives us a univariate polynomial matrix. As before, the drop in rank of this matrix can be reformulated as a generalized eigenvalue problem.
These problems are good examples of how algebraic geometry can be used in concrete cases. While seeming quite simple, these problems require in fact some advanced theory, especially for complex geometrical shapes.
References:
[1] Veach E., Guibas L. J. (1997). Metropolis light transport. Proceedings of the 24th annual conference on Computer graphics and interactive techniques.
09/11/2023 - Equilibria in astrophysics and fluid dynamics
This article was written by Vishrut BEZBARUA and Hans Joans ZEBALLOS RIVERA, based on the presentations given by Hubert BATY and Victor MICHEL-DANSAC on November 9th, 2023.
This article discusses the challenges of simulating fluid flows around equilibrium states, from the sun’s corona to river currents. We’ll also highlight innovative computational strategies for greater precision.
Solar flares are sudden and intense explosions in the solar corona, involving the release of magnetic energy stored in the Sun’s atmosphere. They are sudden and fast, releasing energy equivalent to 1025 times that of the Hiroshima Bomb. Ejected flows have speeds close to 0.01 times the speed of light, and the strongly accelerated particles acquire relativistic speeds. There are energy releases along with the solar flares, which finds its origin in magnetic processes, a prominent example of which is magnetic reconnection. Magnetic reconnection is a fundamental process where the magnetic topology undergoes a sudden rearrangement, converting magnetic energy into kinetic energy, thermal energy, and particle acceleration. This process occurs when magnetic field lines with opposing orientations come into close proximity, leading to the breaking and reconnecting of these field lines and formation of structures called plasmoids which are like self-contained plasma fluid quantities.
To study the dynamics of these plamoids, the complete set of the so-called magnetohydrodynamic (MHD) equations have to be solved: this is a highly intricate task. Numerical methods have to be carefully chosen in order to treat both conservation and diffusive parts of the equations. To simplify the computational challenges associated with solving the MHD equations in such physical regime, researchers often employ reduced models, particularly in two dimensions. In such simplified models, certain complexities inherent in the plasmoid regime can be mitigated, offering advantages in terms of computational efficiency.

Figure 1. A finite element discretization
To perform numerical simulations of such models, a common approach is to consider a finite-element method, which provides a piece-wise polynomial approximation of the physical quantity. This method can be used for a detailed numerical study of magnetic reconnection and tilt instability. In the regime where the Lundquist number exceeds 104, stochastic reconnection, characterized by the presence of numerous plasmoid, becomes prominent. However, problems arise because the number of elements and the calculation time required then increase considerably. The computational limit is reached for a Lundquist number of the order of 106.
Recently, a cheaper alternative has been proposed using a Physics-Informed Neural Network (PINN) approach, which is proving effective for two-dimensional MHD equilibria. PINNs consist in finding out a solution represented by a neural network, whose parameters are optimized to satisfy the physical model at some sampling points. They offer a mesh-free solution without complex discretization. Despite merits, challenges include the non-convex optimization of the parameters and limited extrapolation. Ongoing efforts aim to refine training methodologies, highlighting PINNs’ promise in diverse applications.

Figure 2. Estuary of Gironde
Exploring equilibrium states in astrophysics, such as plasmoids in solar flares using MHD models, alongside AI-enhanced resolution through techniques like PINNs, provides valuable insights into the stability of complex systems. Shifting focus to fluid mechanics, we examine the numerical techniques developed for simulating shallow water flows. Like MHD equations, many fluid models actually describe conservation laws (conservation of mass, momentum, energy): they belong to the class of the so-called hyperbolic equations. Specific numerical methods, called Finite Volume Method, have been developed topreserve these conservation laws at the discrete level. This approach becomes crucial in situations where physical phenomena can generate discontinuities or singularities in the solutions. For instance, these methods were used for numerical simulations of the Saint Venant model, which model tsunamis, or a section of the Gironde estuary (see Figure 2).
The Saint-Venant equations provides the dynamics of the height of water h(x,t) above a topographic level z(x,t) and the volumetric flux q(x,t). In the 1D case, the equations are the following partial differential equations:

where g is the gravity constant and η = 7/3 is the Manning coefficient, which characterizes the friction with the ground level. This system is indeed a hyperbolic system with source term, which can be written under the general form:
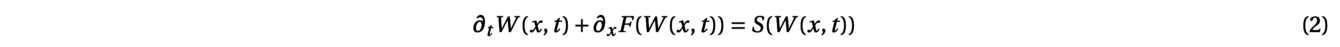
with W(x,t)=(h(x,t),q(x,t)). To discretize such a system with a Finite Volume Scheme, the one-dimensional domain between the border points a and b is subdivided into N subintervals:
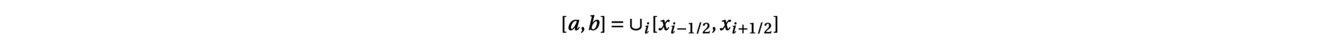
Then, the scheme is inspired from the following integral formulation of the conservations laws obtained after the integration of the equation over the cell [xi−1/2,xi+1/2] between time tnand tn+1:
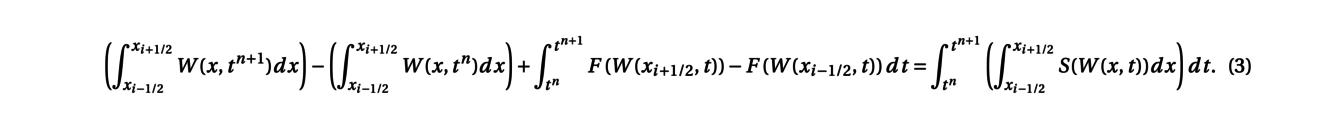
Denoting by Winan approximation of the average of the solution W(x,t) over the cell [xi−1/2,xi+1/2] at time tn, a finite volume scheme thus writes:
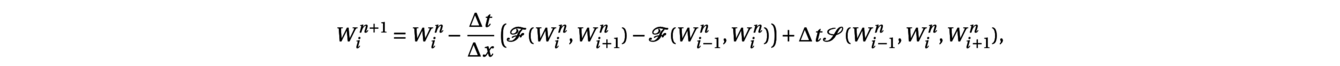
where the function F is the numerical flux function and S the numerical source term. In the absence of a term source, such a discretization preserves the total quantity over the domain:
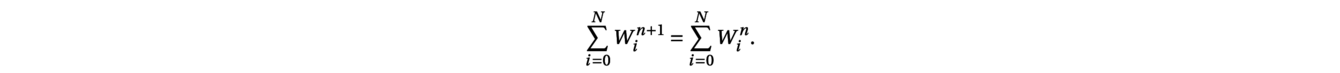
When solving the Saint-Venant system, a key property is to ensure that the method is well-balanced, meaning that it exactly preserves the discrete steady-state solutions. One particular steady state is the lake at rest, with zero flux q = 0 and constant level of the lake, h + z = constant. Such property is crucial to avoid the generation of artificial errors and a classical method for the lake at rest steady state is the so-called hydrostatic recontruction. The function F and S have to be defined such as to satisfy Win+1 = Winwhen starting from a steady state. Recent developments have also made it possible to take moving steady states (with q≠ 0) into account.
In conclusion, whether for the simulation of magnetic reconnection or shallow water fluid mechanics, very elaborate and efficient numerical resolution tools have been studied to faithfully capture either the dynamics around equilibria. Exact preservation of steady states can be prescribed into the numerical method, while new machine learning tools can help to overcome numerical constraints and tackle extended physical regimes.
05-19/10/2023 - Kirkman’s problem and statistical design of experiments
This article was written by Abakar Djiddi YOUSSOUF and Livio METZ, based on the presentations given by Frédéric BERTRAND and Pierre GUILLOT on October 05th & 19th, 2023
"Fifteen young ladies in a school walk out three abreast for seven days in succession: it is required to arrange them daily, so that no two shall walk twice abreast". The most important of this combinatorial problem, known as Kirkman’s problem, is not the solution itself. It is interesting to think on what is related with: finite geometry, combinatorial designs theory (mostly Steiner systems) or, in a more practical aspect, the statistical design of experiments.
As is often the case in mathematics, it could be interesting to first think about generalizing this problem. For instance, for any integer q ≥ 2, we could ask to bring together q2 girls in rows of q during q + 1 days. When q is a power of a prime number, there exists a field named Fq with q elements. We recall that a field is a set on which addition and multiplication are defined and each non-zero elements has an inverse.

Figure 1. Solution to the problem for q=3
This allows us to think the problem in terms of finite affine geometry: we can assimilate girls as points constituting a 2-dimensional vector space on the field Fq: Fq2. Rows will be like affine lines, each containing q points. A line is defined by exactly two points so that two different lines cannot intersect in more than one point. This identification gives us a solution to the problem (see figure for q = 3).
In the cases where q is not a power of a prime number, we do not know if there is a solution, except for the particular values q = 6 or 10. At the same time, our original problem has a solution but there is no affine geometry equivalent.
Another generalization of the Kirkman’s problem are Steiner systems. A Steiner system with parameter (t,k,n), denoted by S(t,k,n) is a set E of n elements together with a collection (Fi) of subsets called blocks, all of cardinality k, such that every subset of E with cardinality t is included in exactly one element Fi. In this context, the previously studied problems boil down to the existence of a Steiner system: S(2,3,15) for the initial Kirkman’s problem and S(2,q,q2) for the generalization. We will now focus on another particular case of the problem: S(5,8,24). Does such a Steiner system exists? The answer is yes and there is a link with the group M24.
The mathematician Émile Mathieu was initially convinced that what will be later called M12 and M24 exist, searching "small" simple 5-transitive subgroups in Sn. Ernst Witt later proved the existence of M24, constructing it as the automorphism group of the Steiner system S(5,8,24): this is the permutation group of the 24 elements preserving the blocks.
The group M24 has for instance its own interest in group theory since it is simple. It is one of the 26 simple groups, called "sporadics", of the simple groups classification. The Steiner system S(5,8,24) is also related to Golay code. The Golay code is used in error correction during data exchanges. It was for instance used within the framework of the Voyager NASA’s program.
Such combinatorial problems are also linked to a practical technique in statistics, called "Statistical Design of Experiments". It is used to plan the smallest possible series of experiments, while guaranteeing the quality of the statistical indicators. Investigating a relation between a response Y and n different factors X1, . . . , Xn using experiments (for instance, Y is the health status and X1 is age, X2 diet, X3 gender) consists into looking for a statistical model:
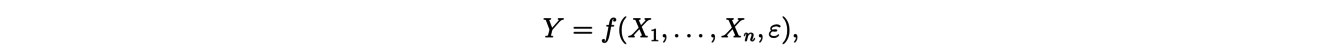
where f is a function depending on several parameters and ε is a random variable viewed as random noise or error. These parameters have to be determined using the experiments. The significance of each factor is assessed using statistical methods like ANOVA (ANalysis Of VAriance).

Figure 2. C is the origin, A are axial points and F vertices of the cube.
Experimental designs have been developed when factors take quantitative values: these are response surface designs. For instance, when the statistical model is a second-order polynomial, a popular design is the central composite design composed of the vertices of a hypercube in dimension n, the origin and axial points with only one active factor (see Figure 2 for n = 3). Choosing the values of the experiments at these points allows to get good estimations of the parameters of the model.
Considering now that all the factors are qualitative and that they can take 2 different values, Completely Randomized Designs consist into picking exactly the same number of experiments for each of the 2n combinations of factors. The symmetry of the experimental plan allows to expect error compensation in the data analysis. The number of experiments then grows exponentially with the number of factors.
Another experimental design is called Balanced Incomplete Block Designs (BIBD): it is particularly suitable for situations where not all factor combinations can be tested. Supposing that the n factors take 0-1 binary values, BIBD organizes the experiments so that each experiment combines exactly k factors, each factor is contained in exactly r experiments and every distinct pairs of factors appears together in exactly λ experiments. Note that if λ = 1, then this is the Steiner system S(2,k,n). This structure ensures that each factor is performed an equal number of times and that each pair of factor coexists in an equal number of experiments, thereby facilitating a balanced and representative analysis of the interactions between factors.
Thus, combinatorial problems can lead to very deep development in finite geometry and group theory but are also at the heart of very practical methods for analysing data.
21/09/2023 - An overview of proof assistants
This article was written by Mathis TRANCHANT, based on the presentations given by Nicolas MAGAUD and Christine PAULIN-MOHRING on September, 21st 2023.
A mathematical demonstration requires another skill in addition to computation, which is reasoning. Here lies the hard part, of building an efficient software to prove things. Amongst the many obstacles there is, we can think of Godel’s incompleteness theorem or the high complexity of some statements, leading to much more complex demonstration paths for the computer to find. On the other hand, once a proof has been found, it is naturally easy to write some code to verify that the proof is indeed flawless using an inference engine relying on a set of known and trustworthy rules. This observation leads to the idea of proof assistants. This is, a digital interface between the mathematician and the machine, with a core algorithm for proof checking, eventually able to fill some small gaps in a demonstration, and the possibility to build libraries if working in a specific part of mathematics.

Figure 1. Coq interface
The history of proof assistants began in the 1970s thanks to the work of Boyer and Moore, with a code called ACL, capable of making induction proofs with the primitive recursive arithmetic, proving simple trivial steps automatically. Later, Milner introduced the idea of tactics, which are programs safely combining primitive rules together. A change of method appeared around 1985 with Isabelle/HOL and Coq, two software based on higher-order logic (HOL) and the later precisely based on type theory. Many of these are still used nowadays. More recently, we can note in 2013 a new assistant, Lean, which uses type theory for mathematical proofs, implementing for example classical logic.
These proof assistants have already proved their worth in many situations. For Coq, let us cite as examples the proof of the 4 color theorem in 2007, the build of an optimizing C compiler, the Javacard protocols security certification, the many uses in cryptography or its use as a base language for the educational software Edukera.
Different languages
Logical proofs require a specific language to write the derivation of true properties from previous ones. For instance, the set theory approach consists in giving few axioms from which we build the mathematical objects by using logical connectives (negation, or, and, implication), and quantifiers (for all, there exists). As we build everything from basic objects, this implies many abstraction layers to hide the complexity of these constructions. Meanwhile, higher order logic and type theory, used in modern assistant proofs, rely on a lighter basis. For instance, when the inclusion relation ∈ of set theory is a primitive property that has to be proven, in higher order logic and type theory, the membership notion takes the form of what is called a typing judgment, written " a: A": the term a has type A and specific rules are associated to objects of type A.
For HOL, two logical primitive operations are used: implication and a generalized version of the "for all" quantifier, also covering propositions. Using these two it is possible to explicitly build most of the mathematical objects needed without speaking of sets.
In type theory, the types are constructed by giving explicit rules. As an example, the natural numbers N is made by giving two judgments, "0: N" and " succ : N → N", where succ is the successor function and has the “function type” from N to itself. They are the constructors of the type N. Denoting 1 := succ(0) and so on, we have built natural numbers. Indeed, we now can derive any function from natural numbers to themselves by a recursive definition: a+b becomes the b-th successor of a, and the function double: x→ 2x is defined with double(0)=0 and double(succ(n))=succ(succ(double(n))) - more generally formalized as a recursive definition on the type N. Moreover, this avoids additional axioms in the sense that every type has an internal definition.
Thus, with type theory, we can define directly many mathematical functions as programs. This is very useful to automate proofs since equality can be proven by evaluation thanks to the underlying program. For example, f(a)=b has a proof if f(a) has the value b. Nevertheless, all functions cannot be defined in this way: for instance, defining the minimum of a function from N to N recursively results into an infinite loop.
Another approach is to use functional terms to represent proofs. This is known as the Curry-Howard isomorphism: " a : A" is interpreted as "a proves A", and thus a function from A to B can be considered as a proof of B knowing A. This way, having some proposition P provable is equivalent to having the proof assistant able to compute a term of the type P, and checking a proof is the same as checking that the types are correct.
Sum of integers
Now that the main ideas of proof assistant using type theory had been given, let us show, as an example of how we can write a proof for the following identity with the Coq Software.
First, we construct the sum of the n first integers like a recursive program by using the constructor of N (nat) and the module Lia Arith for the simple algebra.
Require Import Lia Arith.
Fixpoint sum (n:nat) : nat :=
match n with
O => O
| S p => sum p + (S p)
end.
Then, we define the lemma, and write down the steps the assistant has to follow in order to compute the proof:
Lemma sum_n_n1 :
forall n:nat, (sum n)*2= n*(n+1).
Proof.
intros.
induction n.
reflexivity.
simpl sum.
replace ((sum n + (S n)) * 2) with
((sum n)*2 + (S n)*2) by lia.
rewrite IHn.
lia.
Qed.
In this proof, the first instruction, intros, is meant to add to the context a term of type nat as introduced in the lemma. We then use the induction principle to replace "every n" with two cases: the base case and the induction case with an induction hypothesis. The base case shows up to be trivial, and only results from the fact that equality is an equivalence relation: this is the reflexivity line. We then show the induction case: we simplify the equation to use the hypothesis (IHn), and end with a relation easy enough to be solved by the module Lia.
This proof is, of course, relatively simple, and much more complex ones can be handled with such a language. This is partly thanks to the combination of abstract representation of objects using type theory and computation capabilities. Proof assistants such as Coq are now operational tools in many domains and may help in the future to elaborate new proofs.
06/10/2022 - Dynamical systems and astrophysics
This article was written by Yassin KHALIL and Mei PALANQUE, based on the presentations given by Giacomo MONARI and Ana RECHTMAN on October, 6th 2022.
Stars in a galaxy move on trajectories called orbits, whose study is powerful to help us understand the nature, organization, and dynamics of the components of the galaxy. Indeed, studies of stellar orbits in galaxies (including our own, the Milky Way) lead to the theory of dark matter, as well as to our understanding of the velocity distribution of stars around the Sun. All this would not be possible without some astonishing mathematical developments that we shall explore, before discussing those remarkable achievements in astrophysics.
We start with the coordinates y(t) of a star in a galaxy. They are solutions of dynamical system:
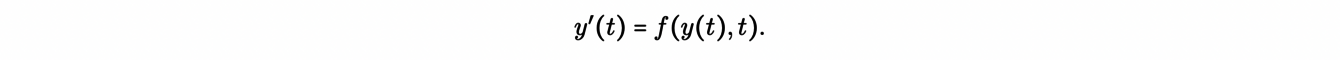
So, given the initial position and velocity of the star y0, its orbit (meaning the time evolution of y(t)) will be a solution to this differential equation. We then consider the flow φ associated with this dynamical system, which gives the solution at time t for any initial condition: φ(y0,t) =y(t). As you may notice, f(y(t),t) determines the dynamics. In the case of stellar orbits, dynamics is usually Hamiltonian, which has some important implications as we will see next.
To start, we consider a set of canonical coordinates y(t) =(q1(t),...,qn(t), p1(t),.. ,pn(t)), where (qi(t)) are the positions and (pi(t)) the momenta. Then, with the Hamiltonian H(y(t)) of the system, which is, in many cases, the energy of the system, the equations of motion of the system given by:
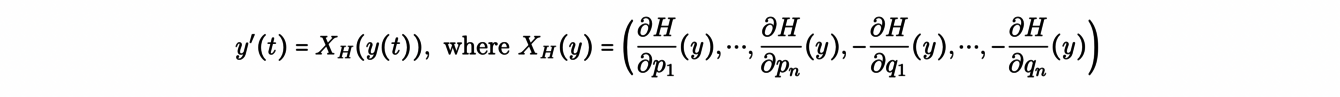
or equivalently:
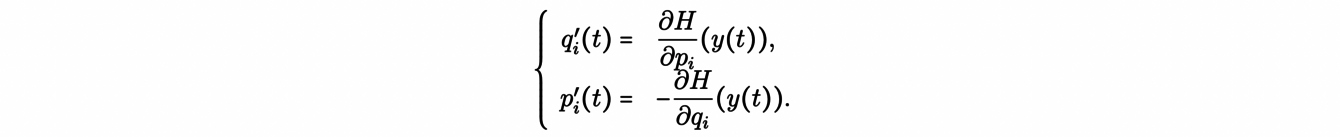
Then, for this Hamiltonian dynamical system, the equations of motion generate a Hamiltonian flow φH for an initial condition y0 = (qi0,pj0), given by:
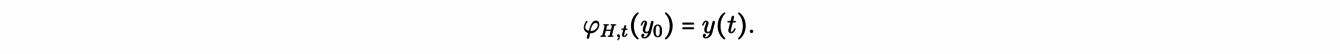
One important property of such a system is that the Hamiltonian H(y(t)) is conserved along the orbits. Consequently, the orbits are confined to the isosurfaces of the Hamiltonian function, i.e. on the hypersurfaces H-1(c).
To further study the hamiltonian flow and the orbits of stars, we can resort to the concept of the Birkhoff section: this is a compact (bounded) surface whose interior is transverse to the flow and which cuts any orbit of the system. In some cases, where the physical orbits are close to ideal periodic orbits, the whole dynamics can be resumed by the time-discrete dynamics on the Birkhoff section: this is a corolarry of the Poincaré-Birkhoff theorem.
In practice, the study of Hamiltonian systems and the analytical resolution of the equations relies also on the concepts of constants of motion and integrals of motion. Constants of motion are functions of the phase-space coordinates and time C(y,t) that are constant along an orbit. We note that any orbit has at least 2n of them, its initial positions, and momenta, with n the dimension of the problem. Integrals of motion are functions of the phase-space coordinates alone I(y) , constant along an orbit. Stellar orbits can have from 0 to 5 of them. The Hamiltonian itself is an integral of motion, when it depends only on the coordinates y and not on time.
In the context of galaxies, in principle billions of stars interact with each other (and with the interstellar medium and dark matter) through gravitational attraction. However, in practice, the effect of individual encounters between stars is minimal and the orbits of stars are mainly determined by the mean gravitational field (and corresponding potential Φ) of all the stars and massive components of the galaxy, the dynamics being in this case called “collisionless”.
Now, we may wonder how does the study of the stellar orbits enable us to infer some key properties on the galactic potential Φ and of the galactic structure itself? A sizable fraction of all observable galaxies in the universe are spiral galaxies that have roughly the shape, in their visible components, of a rotating disk of stars. For these galaxies, the cylindrical coordinates (R,ϕ,z) are best suited to describe the orbits of stars. In these coordinates, the tangential velocity is defined as:

The use of tangential velocities of stars and gas allow us, in some cases, to constrain a galaxy’s potential and mass distribution.
To do this, we first assume that the galaxy’s potential has no preferential direction on the disk of stars of a spiral galaxy. This is the case of an axisymmetric galactic potential Φ(R,z). The circular orbits in this potential are possible only on the galactic plane z=0, and have the angle coordinate increasing as
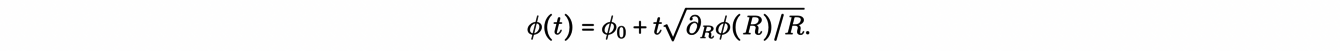
Therefore, the tangential velocity of a circular orbit vc is a function of R:
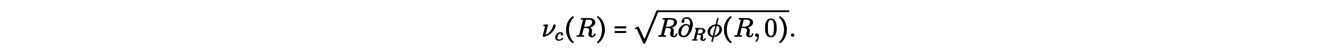
The variation of the tangential velocity then depends on the galactic potential Φ and hence, on the total mass distribution of the galaxy. Thanks to radio astronomy and the 21 cm hydrogen line, we can measure the tangential velocity of gas in many spiral galaxies. The gas moves on practically circular orbits, giving us a measurement of vc at different distances R of the galaxy center.
 as a function of the distance R to the galaxy center, for a spiral galaxy similar to the Milky Way (here, the Andromeda galaxy M31)</em>")
Figure 1. Representation of measured and predicted circular velocity vc(R) as a function of the distance R to the galaxy center, for a spiral galaxy similar to the Milky Way (here, the Andromeda galaxy M31)
We can then use the above formula to compute the potential Φ(R,0), which depends on the mass distribution of the galaxy. When we do so, we find that vc(R) is almost constant in the outer part of most galaxies, which corresponds to much more mass than estimated by directly evaluating it from the amount of visible matter (mainly stars and gas). This is the dark matter enigma! The missing mass in the difference must be somehow non-luminous: this is why we call it dark matter.
Another application of the concepts discussed so far concerns the velocity dispersion of stars in the neighborhood of the Sun. This requires the study of non-circular orbits, which, unfortunately, are not, in general, analytically integrable. However, we can still study them using the so-called epicyclic approximation. To understand the epicyclic approximation, first, we note that the z-component of the angular momentum Lz=Rvc(R) is an integral of motion, with the plane of the disk being perpendicular to z. Then, we can define an effective galactic potential:
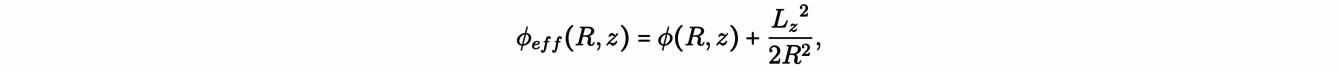
as well as an equivalent circular radius Rg , called the guiding radius, for the non-circular orbit of angular momentum Lz:
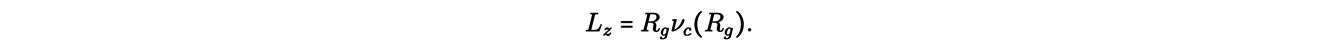
Considering a second order approximation of the effective potential around(R,z) =(Rg,0), the dynamics can be approximated by two harmonic oscillator equations: one for the dynamics of (R -Rg) in the galactic plane (z=0) with frequency κ, and another for the z-component dynamics, with frequency υ.
 is well approximated by the orbit obtained by the superposition of 1) the motion at angular frequency κ around a small ellipse with axis ratio 1/2 and 2) the motion of the ellipse’s center in the opposite sense at angular frequency Ω around a circle (dotted curve).</em>")
Figure 2. The elliptical orbit (dashed curve) is well approximated by the orbit obtained by the superposition of 1) the motion at angular frequency κ around a small ellipse with axis ratio 1/2 and 2) the motion of the ellipse’s center in the opposite sense at angular frequency Ω around a circle (dotted curve).
The projections of the orbits on the galactic plane look like the one presented in Figure 2. The axis ratio of the orbit ellipses equals √2 when the galactic potential leads to a constant tangential speed vc(R) and this is approximately the case for the Milky Way, at least not too close to its center. Indeed, measurements of velocity dispersion for stars close to the sun enable us to estimate an axis ratio close to √2, which in turn corroborates the flat tangential speed inside our Galaxy.
What we have said so far may give an idea of how fascinating galaxies are and how complex is the study of their dynamics. In particular, we focused on the dynamics of stellar orbits. We briefly presented some decisive mathematical concepts enabling us to have a deeper insight into issues such as the distribution of dark matter in galaxies.
However, the physical reality of disk galaxies is far more complex than these zero-order models. Indeed, galaxies are not axially symmetric. Bars and spiral arms break the symmetry of most disks.
Feynman already said in 1963, “the exact details of how the arms are formed and what determines the shape of these galaxies has not been worked out”. As for today, dynamical modeling of galaxies in the presence of non-axisymmetric perturbations remains a complicated undertaking which requires advances in astrophysics and mathematics.
08/09/2022 - Ehrhart polynomials and code optimization
This article was written by Lauriane TURELIER and Lucas NOEL, based on the presentations given by Philippe CLAUSS and Thomas DELZANT on September, 8th 2022.

Figure 1 - Polytope representation for d=2
The mass use of computers and computing nowadays, for various reasons, means that we are constantly looking for methods to reduce the execution time of algorithms. Thanks to the mathematician Ehrhart and his discovery of a certain class of polynomials, a method to reduce computation times has been brought to light, in particular to optimize the storage of information and reduce the computing time. What about these polynomials and how have they allowed us to simplify the algorithmic structures of programs ?
To define these polynomials, we consider a polytope ∆, which is the generalization of a polygon in large dimension. The Ehrhart polynomial associated to ∆, denoted P∆ is defined by:
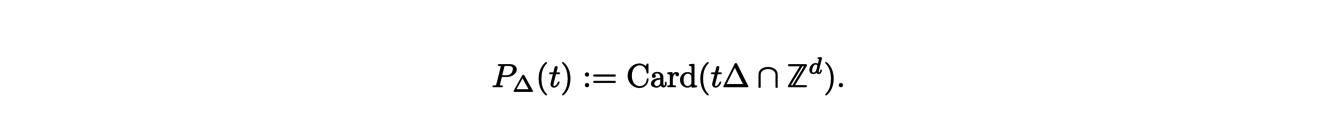
It counts the number of points with integer coordinates that the polytope t∆ contains where t∆ denotes the dilation of ∆ by a factor t.
This quantity is naturally associated to combinatory problems. For instance, let us look at the following concrete example : ”how many ways can you pay n euros with 10, 20, 50 cent and 1 euro coins”. In arithmetics, this is equivalent to solving the following diophantine equation:
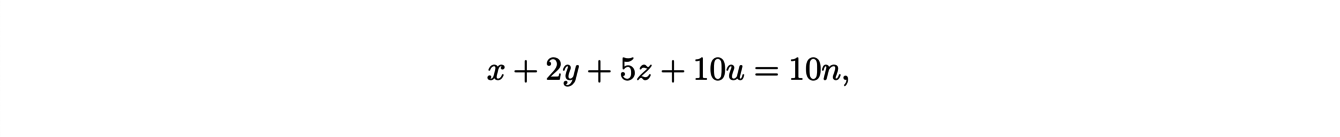
where x, y, z and u are integers. To find these solutions, we introduce the polytope ∆ of R4 defined by the following equations:
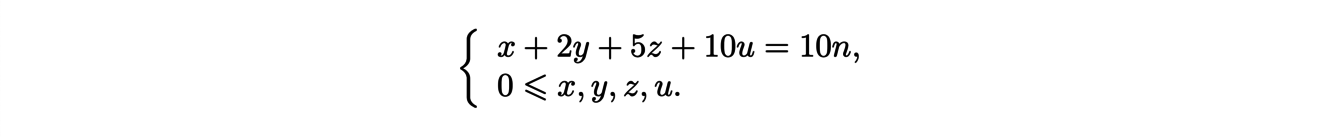
To solve the initial problem, we have to find the number of points with integer coordinates in this polytope. This is given by the associated Ehrhart polynomial. After calculation, we can find that the polynomial is written:
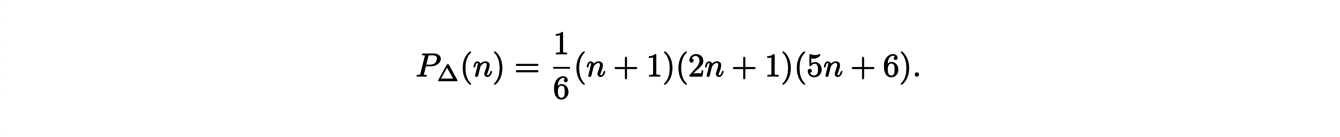
After introducing these polynomials, let us highlight some of their properties.
For some polytopes, the Ehrhart polynomials can have an explicit expression. The polytope ∆d+1 defined as the convex hull of the points {0,1}d ×{0} and the point (0,...,0,1) in Rd+1 is represented in Figure 1 for d = 2.
We can see that 5∆2 can be obtained as the union of a translation of 4∆2 along the vertical axis and the square basis of size 5.
It follows that
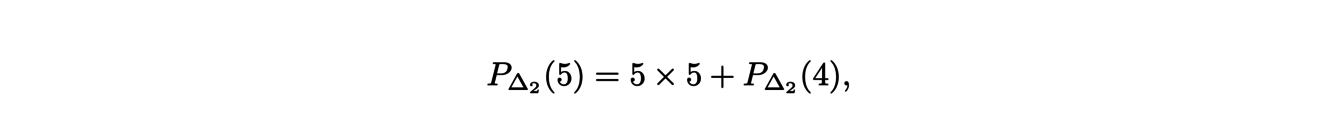
and, then for any n,
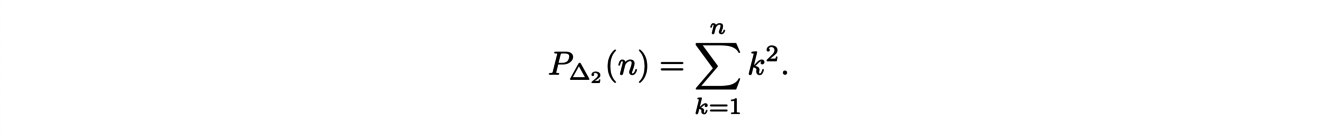
These arguments extend to the dimension d and lead to the following formula:
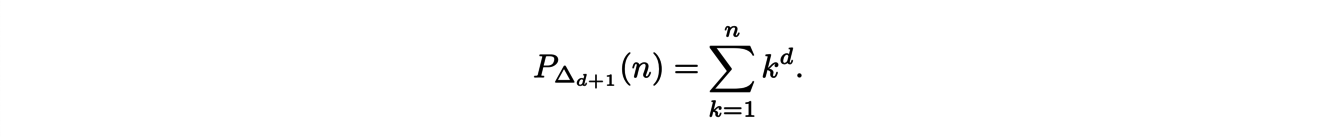
Surprisingly, this expression is not a polynomial ! However, it is possible to write it in polynomial form:
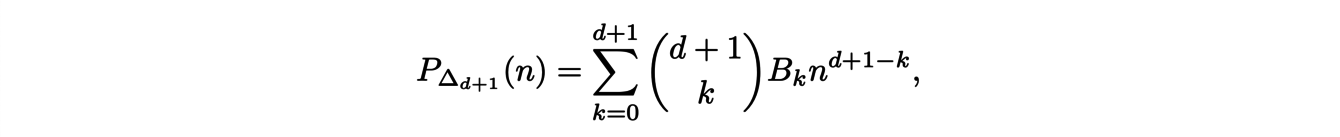
where (Bk)k∈N are the Bernoulli numbers. We thus have an explicit expression for the coefficients of these Ehrahrt polynomials. But what can we say if we consider any other polytopes ?
We are able to give a geometric interpretation as well as the explicit expression of some coefficients of the Ehrhart polynomial
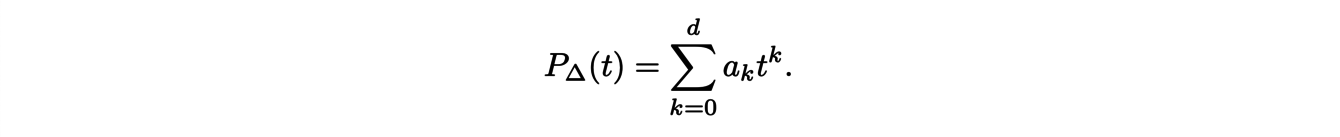
Indeed, the dominant coefficient ad is equal to the volume of ∆ and the second coefficient ad−1 is related to the number of points with integer coordinates on the boundary:
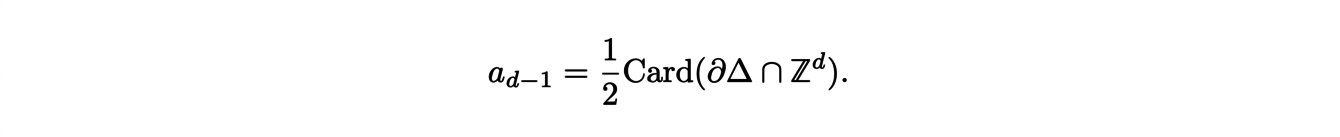
Also, the constant coefficient is equal to 1, since if we evaluate the polynomial at 0, we find the number of points in 0∆ which is none other than the origin. With all these information, we can explicitly determine the expression of the Ehrhart polynomial of two-dimensional polygon ∆:
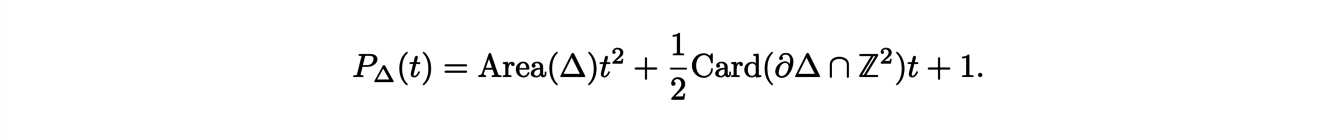
Although the Ehrhart polynomials still raises a lot of mathematical questions, it has recently found applications in computer science.

Figure 2
In computer science, it sometimes happens that even simple programs take a long time to be executed. This can be due to a problem of storage and access to the information during the execution, in particular when passing through nested loops. To alleviate this problem, we can use ranking Ehrhart polynomials and their inverses.
Ranking Ehrhart polynomials are generalizations of Ehrhart polynomials : to any polytope ∆, we associate the polynomial P∆ with d variables such that P∆(i1, · · · , id) equals the number of points with integer coordinates contained in ∆ that are smaller than (i1, · · · , id) for the lexicographic order. For each points (i1, · · · , id), P∆(i1, · · · , id) is actually a sum of Ehrahrt polynomials associated to different polytopes. In particular, P∆(i1, · · · , id) is the rank of i1, · · · , id in ∆ when sorting elements in lexicographic order.
How can it be used ? Consider the following piece of program:
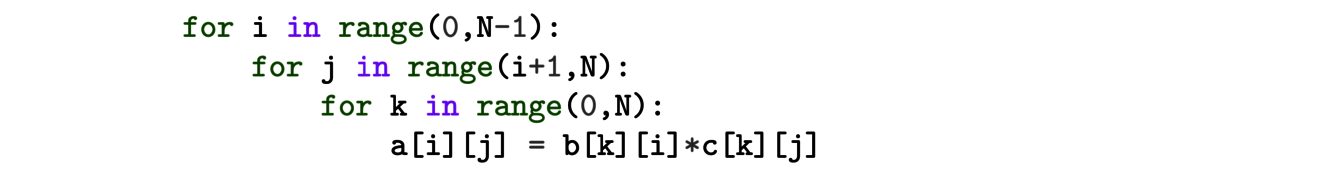
where a, b and c represent N × N arrays. In the computer memory, the values of the matrices a, b and c are stored line by line. However, the program does not access them in this order and then spends a lot of time. It would be better to store the data in the order they are visited by the algorithm. To do that, we consider the following polytope:

The integer points of ∆ correspond to all the triplets present in the loops. Then arrays a, b and c can be next stored using the rank of the elements given by the Ehrhart polynomial. This can be further used to rewrite the loops and optimize the parallell execution of the program on several processors.
In conclusion, Ehrahrt polynomials have some very beautiful mathematical properties but still hold some mysteries. Nevertheless, this does not prevent us from using them in very concrete problems in computer science. Ehrhart polynomials have been a very useful discovery nowadays to reduce the computation time of algorithms.
ANNEX

02/12/2021 - Transport optimal et astrophysique
Cet article a été écrit par Claire SCHNOEBELEN et Nicolas STUTZ, à partir des présentations de Nicolas JUILLET et Bruno LEVY du 02 Décembre 2021.
![Transport optimal discret-discret (gauche) et discret-continu (droite) (Source : [1])](/websites/_processed_/f/a/csm_f7-1_2dc4d60963.png "<em>Transport optimal discret-discret (gauche) et discret-continu (droite) (Source : [1])</em>")
Transport optimal discret-discret (gauche) et discret-continu (droite) (Source : [1])
La théorie du transport optimal a débuté à la fin des années 1770. Le mathématicien Gaspard Monge formalisait alors le problème des « déblais et remblais ». Historiquement, on cherchait à déplacer un tas de terre d’une région initiale de l’espace (appelée déblais) en modifiant éventuellement sa forme, vers une région finale (appelée remblais) de façon optimale. Il s’agit en fait d’un problème de déplacement qui décrit des situations plus générales, où l’on pourrait aussi bien considérer que la masse à transporter représente un gaz, un liquide, un nuage de points, ou encore des niveaux de gris dans le cadre du traitement d’images.
Les problèmes dits de « matching » sont des exemples naturels de problèmes de transport, nous allons en expliciter un. Donnons-nous un entier naturel n et considérons n mines x1 , . . . , xn d’où est extrait un minerai, ainsi que n usines y1, . . . , ynutilisant ce minerai comme matière première. On cherche à associer à chaque mine xiune usine yj de sorte à minimiser le coût total de transport. Pour modéliser le problème, notons c(xi,yj) = cij le coût de déplacement d’un minerai depuis une mine xi jusqu’à une usine yj. La résolution du problème se réduit alors à la recherche d’une permutation σopt telle que
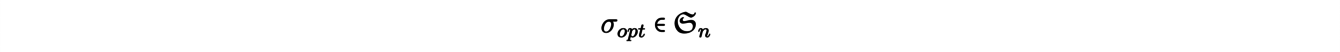
et qui est solution du problème de minimisation suivant :
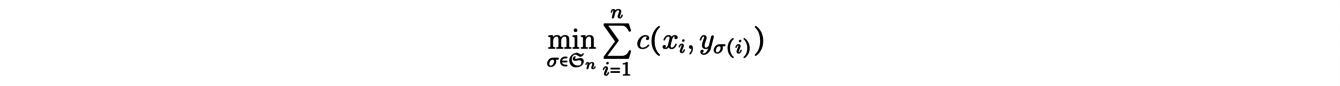
Remarquons en particulier que le problème et ses solutions potentielles dépendent de la fonction coût choisie. Dans notre exemple, on pourrait identifier les mines xi et les usines yjavec des points d’un espace euclidien et considérer des fonctions coût de type « distance », c’est-à-dire
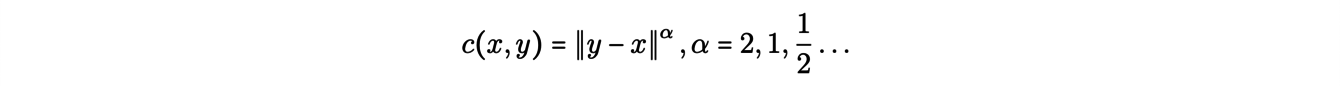
Une propriété remarquable de la théorie du transport discret apparaît dans ce contexte comme conséquence de l’inégalité triangulaire : les routes de transport optimales ne s’intersectent pas. Par ailleurs, on peut reformuler le problème ci-dessus. Formellement, on cherche une application Topt solution du problème de minimisation :
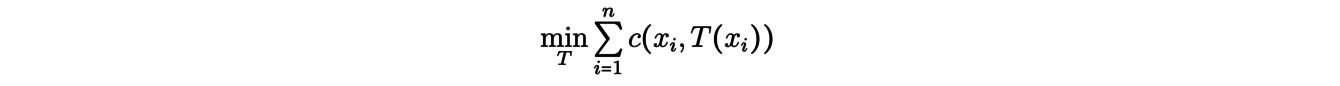
On peut généraliser le problème précédent de la façon suivante. On considère toujours n usines à livrer mais il y a désormais m ≠ n mines produisant le minerai. Avec la modélisation précédente, si m < n, la fonction de transport optimale ne sera pas surjective et certaines usines ne seront livrées par aucune mine.
La formulation de Kantorovich du problème de transport tient compte de ce problème : il s’agit de répartir le minerai issu de chaque mine sur plusieurs usines. Plus précisément, on affecte des masses p1,...,pm (resp. q1,...,qn) aux mines x1,...,xm (resp. aux usines y1,...,yn) en imposant qu’il y ait autant de minerai à la source qu’à la demande
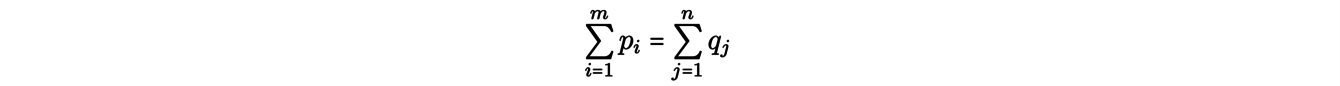
Le problème devient alors d’affecter des masses aux m×n routes de transport, c’est-à-dire à trouver une matrice, appelée « plan de transport » :
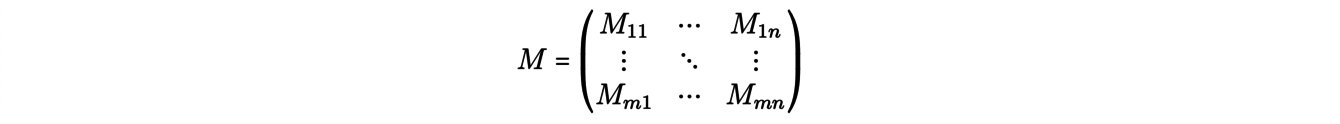
(où Mij ≥ 0 représente la masse transportée de xi à yj) comme solution du problème de minimisation :
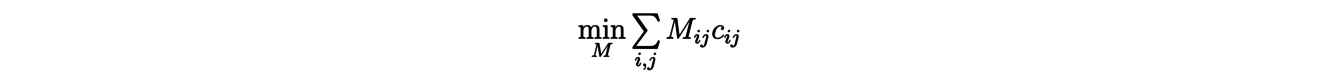
en respectant la conservation des masses sortante et entrante :
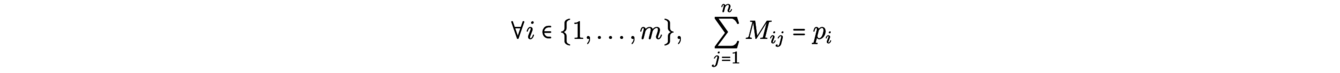

Jusqu’à présent nous n’avons traité que de problème de transport discret. Il existe un formalisme plus général dans lequel la masse déplacée est représentée à l’aide de mesures de probabilité, pouvant être discrètes ou continues. Le problème de transport de Kantorovich dans sa formulation générale prend alors la forme suivante : considérant deux mesures de probabilité
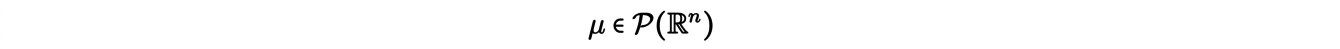
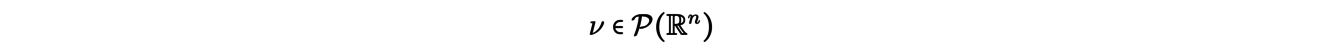
(penser à la première comme au déblais, à la seconde comme au remblais), on cherche πoptune mesure (un plan de transport) solution du problème de minimisation
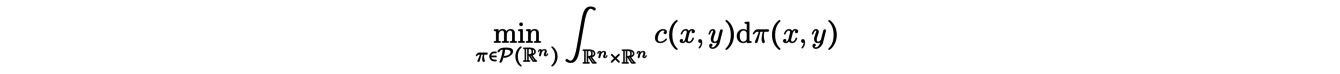
avec les équations aux marges (conditions de conservation de la masse) suivantes :
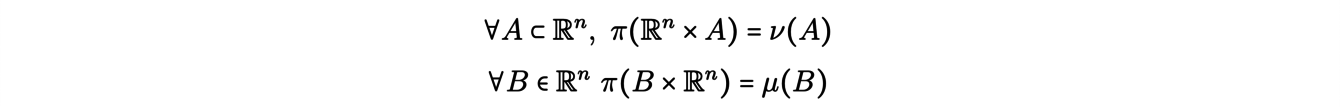
L’aspect algorithmique lié au problème de transport optimal a été source de nombreux travaux depuis ceux du mathématicien Leonid Kantorovich au milieu du 20e siècle. En astrophysique, la théorie du transport optimal est notamment utilisée pour reconstituer les grands mouvements de matière des débuts de l’Univers. Il s’agit plus précisément de trouver le processus de transport qui, d’une distribution spatiale uniforme aux débuts de l’Univers, a abouti aux structures actuelles.
Dans une approche classique, les agglomérats de matière actuels sont représentés par un ensemble de points de l’espace Y = (yj)j∈J, répartis selon les observations actuelles. De la même façon, la matière aux débuts de l’Univers est représentée par un ensemble X = (xi)i∈I de points uniforméments répartis dans l’espace. Il s’agit ensuite de trouver l’application T ∶ X → Y qui à chaque point de X associe le point de Y sur lequel la matière correspondante a été envoyée avec le temps.
Pour rendre compte de façon satifaisante du processus de transport, il faudrait que X comporte un grand nombre de points. Mais trouver T revient en fait à trouver l’application I → J correspondante et relève donc de la combinatoire. De ce fait, les algorithmes exploitant une modélisation discrète-discrète de ce problème sont de complexité quadratique. Ainsi, il devient vite très coûteux numériquement de les mettre en oeuvre avec X de grande taille.
Un moyen d’éviter ce problème consiste à considérer le "cas limite" dans lequel X contiendrait tous les points de l’espace. Le problème ainsi reformulé relève alors du transport semi-discret, dans lequel la distribution initiale ρ(x) est une densité uniforme et la distribution d’arrivée
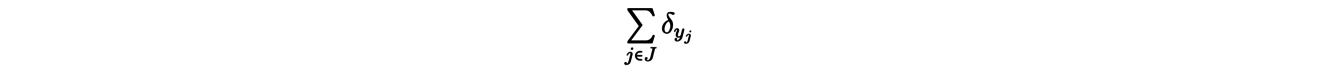
est discrète. Dans ce nouveau problème, le coût minimisé par la fonction de transport T est donné par :
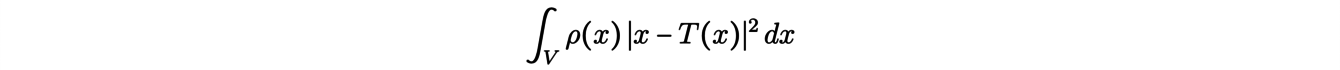
![Reconstruction du champ de densité cosmologique initial (Source : [1])](/websites/_processed_/c/7/csm_f7-2_b0475d4ca8.png "<em>Reconstruction du champ de densité cosmologique initial (Source : [1]) </em>")
Reconstruction du champ de densité cosmologique initial (Source : [1])
où x représente un élément de masse de l’espace V inclus dans R3 et ρ la densité initiale. Il est alors possible de montrer que dans ce cas, ce sont des portions de l’espace, appelées cellules de Laguerre, qui sont envoyées sur des points.
Afin de déterminer ces cellules de Laguerre associées au transport optimal, le problème précédent est reformulé sous sa forme duale, comme un problème de maximisation. Ce problème peut alors être résolu efficacement avec un algorithme de Newton. Finalement, la reconstruction numérique du transport de la matière dans l’Univers peut se faire en O(N log N) où N désigne le cardinal de l’ensemble Y, ce qui est un progrès considérable par rapport aux algorithmes combinatoires.
On voit ici qu’un changement de point de vue ramène le problème discret initial à un cas a priori plus complexe car mettant en jeu un espace continu, mais permet en fait de le traiter numériquement de manière plus efficace.
Références :
[1] Lévy, B., Mohayaee, R. & von Hausegger, S. (2021). A fast semi-discrete optimal transport algorithm for a unique reconstruction of the early Universe. Monthly Notices of the Royal Astronomy Society.
18/11/2021 - Ondelettes et astrophysique
Cet article a été écrit par Robin RIEGEL et Claire SCHNOEBELEN, à partir des présentations de Erwan ALLYS et Philippe HELLUY du 18 Novembre 2021.

Compression d'image à l'aide d'ondelettes
L’analyse d’une image, représentée par une matrice codant le niveau de gris de chaque pixel, consiste en une série d’opération mathématiques qui permettent de mettre en évidence les composantes importantes utiles pour les analyses et traitements futurs. La méthode des ondelettes constitue un outil remarquablement efficace pour cela. Par le biais de convolutions successives du signal avec des fonctions que l’on appelle «ondelettes», cette méthode permet d’obtenir les informations relatives à l’amplitude et aux phases à différentes échelles, ainsi qu’aux interactions entre échelles. Pour un signal composé de 2J points, la méthode consiste à calculer J + 1 séries de 2j coefficients, notés sj,k pour j allant de 0 à J et k allant de 0 à 2j −1. Ces coefficients sont obtenus en effectuant une convolution entre le signal et des fonctions φj,k, appelées «ondelettes filles», toutes obtenues par translation et dilatation d’une unique fonction φ, appelée «ondelette mère».
Différentes ondelettes mères peuvent être employées. Celles de Daubechies sont par exemple très utilisées pour la compression d’images. Dans ce cas, les coefficients sont en pratique obtenus par récurrence, en partant de la série J, constituée des points du signal : on obtient les coefficients de la série j en effectuant une combinaison linéaire de coefficients voisins dans la série j + 1. Une autre combinaison linéaire des mêmes coefficients donne ce qu’on appelle les «détails» dj,k. La dernière étape produit ainsi un unique coefficient s0 et 2J − 1 détails. Contrairement à la méthode de Haar dans laquelle ces derniers s’annulent uniquement dans le cas où le signal est localement constant, les combinaisons linéaires qui interviennent dans la méthode de Daubechies sont choisies de telle sorte que les détails s’annulent également quand le signal est localement linéaire. Le signal original peut être entièrement reconstitué à partir du coefficient s0 et des détails non-nuls calculés à la dernière étape. De plus, la suppression des coefficients proches de zéros n’entraîne qu’une perte minime de l’information et constitue donc une méthode très efficace pour la compression de signal. Cet algorithme, appliqué aux lignes puis aux colonnes de pixels des images, est notamment utilisée pour les compresser dans le format de stockage JPEG2000.
Une autre ondelette mère, celle dont il sera question dans la suite, est celle de Morlet, obtenue en multipliant une gaussienne par une exponentielle complexe :
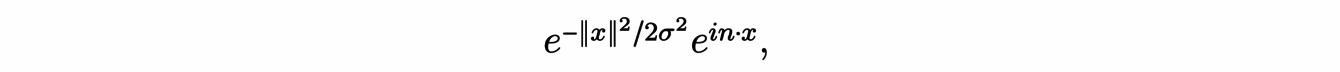
avec n un vecteur du plan et σ > 0 le paramètre d’échelle de la gaussienne. La convolution avec une de ces ondelettes agit comme un filtre passe-bande sur le signal planaire qui permet donc de quantifier les variations dans la direction n à l’échelle 1/σ.
Ce type d’ondelette peut ainsi être utilisé pour mettre en évidence les interactions entre échelles dans un signal donné. Il revêt donc un intérêt particulier dans l’analyse des images astrophysiques, plus particulièrement dans l’analyse des structures du milieu interstellaire (ISM). En effet, sur les images dont on dispose, ce dernier n’a pas l’aspect d’un champ gaussien, entièrement caractérisé par son spectre de puissance et sans interactions entre échelles. Au contraire, les interférences constructives entre les différentes échelles induisent des structures complexes que l’on voudrait analyser. Une technique très performante pour étudier les images consiste à utiliser des réseaux de neurones mais elle s’avère difficile à mettre en oeuvre dans notre cas, en raison du nombre restreint de données disponibles. Grâce à la méthode des ondelettes, il est toutefois possible d’imiter ces traitements de façon totalement contrôlée et à partir d’une seule image.
Il s’agit pour cela de calculer trois séries de coefficients, la Wavelet Scattering Transform, en convolant l’image I avec les ondelettes dont il était question dans le paragraphe précédent :
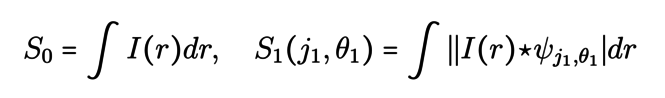
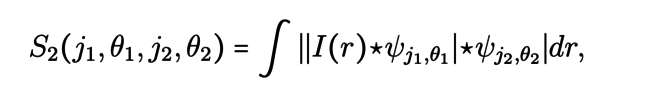
où j1,j2 et θ1,θ2sont respectivement les échelles et les directions des ondelettes considérées. Le premier coefficient rend compte de la valeur moyenne de l’image I et ceux de la deuxième série permettent d’isoler les composantes de l’image liées à une direction et à une échelle donnée. La troisième série de coefficient rend compte des interactions entre échelles et directions. Le point clé dans ces formules est l’utilisation du module des images qui permet d’introduire une non-linéarité. Tout comme dans les réseaux de neurones, cette opération non-linéaire permet de mettre à jour les interférences entre les différentes échelles.
 </em>")
Calcul du moment des Phase Harmonic Wavelets (Source : [1])
Une autre opération non-linéaire que l’on peut introduire est l’harmonique de phase. Cette opération permet alors de construire des statistiques dites Wavelet Phase Harmonics (WPH) en quatre étapes. On commence par filtrer une image à deux échelles différentes puis on effectue une harmonique de phase qui modifie la phase de l’une des deux images pour obtenir deux images de même phase maintenant corrélées. On peut alors calculer les différents moments de covariances de ces images et à partir de ces derniers construire les statistiques WPH. Les moments calculés permettant de quantifier les interactions entre deux échelles données, les statistiques WPH d’une image caractérise sa structure. Connaissant ces statistiques, il est ensuite possible de géné- rer une grande quantité d’images ayant les mêmes propriétés. On obtient ainsi un modèle génératif.
Une application majeure de ce modèle génératif est l’étude du fond diffus comoslogique ou Cosmic Microwave Background (CMB) permettant d’en apprendre plus sur la formation de notre univers et de ses grandes structures. En effet, il est difficile de séparer le CMB des structures tels que la voie lactée ou les étoiles. Les statistiques WPH permettent alors de simuler une grande quantité d’images de ces avants-plans à partir d’une unique autre image. Ces derniers ayant une structure non-gaussienne, contrairement au CMB, on peut alors entraîner un réseau de neurones à effectuer la séparation et ainsi obtenir les données utiles à l’étude du fond stellaire.
La méthode des ondelettes est donc un outil central pour l’analyse multi-échelle d’images. Particulièrement adaptée pour la compression d’images, elle nécessite des extensions pour mieux rendre compte des interférences entre échelles et pourrait aider ainsi à mieux observer le fond diffus cosmologique pour une meilleure compréhension de l’évolution de l’Univers.
Références :
[1] Allys, E., Marchand, T., Cardoso, J. F., Villaescusa-Navarro, F., Ho, S., & Mallat, S. (2020). New interpretable statistics for large-scale structure analysis and generation. Physical Review D, 102(10), 103506.
04/11/2021 - Géométrie discrète pour les images et les nuages de points
Cet article a été écrit par Victor LE GUILLOUX et Lucas PALAZOLLO, à partir des présentations de Etienne BAUDRIER et Quentin MERIGOT du 04 Novembre 2021.
</em>")
Une forme et sa numérisation (Source : [1])
La géométrie discrète permet d’élaborer différents outils mathématiques pour caractériser la géométrie et la topologie d’objets contenus dans une image, c’est à dire la forme d’un sous- ensemble de pixels ou de voxels d’une image. Ces outils sont notamment utilisés en imagerie biomédicale ou encore en science des matériaux. À partir d’une partition d’image ou même d’un nuage de point, on cherche à obtenir une modélisation efficace grâce à de nombreux estimateurs pour calculer des longueurs ou encore pour modéliser précisément ses courbures et ses arrêtes.
Pour calculer des quantités géométriques discrètes d’un objet comme son volume, sa longueur ou encore sa courbure, il est indispensable d’utiliser des estimateurs qui convergent vers les quantités géométriques continues qui nous intéressent lorsque la résolution de l’image devient de plus en plus grande. Ce type de convergence est appelé convergence multigrille. Notons h le pas de discrétisation de la grille, la taille des pixels, Ɛ̃ l’estimateur discret, Ɛ la caractéristique géométrique continue et F une famille de forme. Alors la convergence de l’estimateur peut s’écrire :
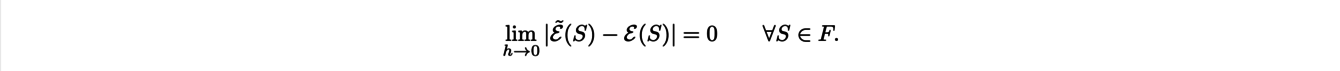
Considérons l’exemple de l’estimateur de périmètre. On peut tout d’abord penser à compter le nombre de déplacement élémentaires : on compte le nombre de déplacements horizontaux et verticaux en suivant les pixels au bord de la forme étudiée. Cependant, on se retrouve à calculer le périmètre du rectangle dans lequel notre forme est inscrite ce qui n’en fait absolument pas un estimateur fiable. Plus généralement, il est possible de montrer que des estimateurs basés sur les déplacements élémentaires sont voués à l’échec car ils ne convergeraient que pour un ensemble de segments dénombrable.
</em>")
Détection d'arêtes dans un nuage de points (Source : [2])
Une solution consiste à estimer la longueur par polygonalisation, c’est à dire en discrétisant la courbe par des segments de droite. Les segments de droite forment un polygone dont le périmètre est facile à calculer. Pour résoudre ce problème, on utilise un algorithme qui permet de détecter si les pixels appartiennent à un même segment de droite discrétisé. Ainsi on recherche l’ensemble des plus grands segments de droite. Il est possible de démontrer que cet estimateur converge en O(h1/2). Dans l’algorithme précédent, on utilise, comme motif, les segments de droites maximaux mais il est tout à fait possible d’utiliser d’autres méthodes en changeant de motifs.
Lorsque la forme est obtenue à l’aide de mesures, celle-ci n’est plus définie comme un sous- ensemble connexe de pixels mais comme un nuages de points. Des méthodes spécifiques ont donc été proposées comme les méthodes dites d’inférence géométrique basée sur la distance. Étant donné un objet K, on peut par exemple retrouver des informations sur sa courbure en utilisant un voisinage tubulaire de K, c’est-à-dire en considérant tous les points situés à une distance inférieure à une distance donnée (le paramètre d’échelle) de l’objet K en question. Si r ≥ 0 désigne le paramètre d’échelle, notons Kr le voisinage tubulaire de K pour le paramètre r. Le premier résultat sur ces voisinages tubulaires est le théorème de Weyl, indiquant que le volume d-dimensionnel du voisinage tubulaire Kr est une fonction polynomiale de degré d sur un certain intervalle, dont la taille est précisée par le théorème de Federer. Plus précisément, le théorème de Federer décrit la mesure de bord de K. Cette mesure donne un poids à tout sous-ensemble B de K de la façon suivante :
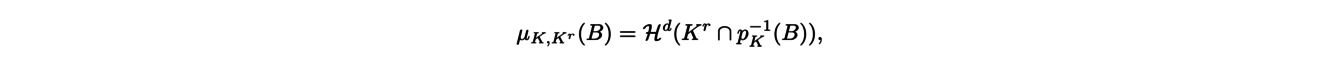
où Hd désigne le volume d-dimensionnel et pK désigne la projection sur K. Cette mesure contient l’information de l’importance de la courbure locale de K en B car elle donne un poids plus élevé aux sous-ensembles de forte courbure. Le théorème de Federer indique alors qu’il existe des mesures signées Φ0, . . . , Φd telles que pour r suffisamment petit :
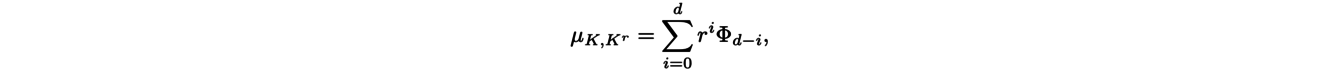
et ce sont ces mesures signées qui contiennent l’information sur la courbure locale de K, notamment sur les éventuelles arêtes de K.
Se pose alors la question de savoir comment calculer, dans la pratique, la mesure de bord d’un objet. Pour réaliser ce calcul, on utilise une méthode dite de type Monte-Carlo. Cette méthode consiste à choisir un grand nombre de points au voisinage de l’objet, et les utiliser pour calculer un estimateur discret de la mesure de bord : chaque point est en quelque sorte projeté sur le bord de l’objet et donne un poids positif au lieu de projection. La probabilité que l’on obtienne de cette manière une mesure approchant bien la mesure de bord se retrouve alors d’autant plus forte que l’on augmente le nombre de points d’échantillonnage.
On peut constater grâce à ces exemples la diversité des méthodes utilisées dans l’estimation discrète d’objets continus afin restituer au mieux leurs propriétés géométriques et topologiques. La géométrie discrète fournit des outils robustes et efficaces. De plus, des études mathématiques poussées sont nécessaires pour déterminer la précision des différents estimateurs et d’assurer leur pertinence pour les problèmes considérés.
Références :
[1] Lachaud, J.O., & Thibert, B. (2016). Properties of Gauss digitized shapes and digital surface integration. Journal of Mathematical Imaging and Vision, 54(2), 162-180.
[2] Mérigot, Q., Ovsjanikov, M., & Guibas, L.J. (2010). Voronoi-based curvature and feature estimation from point clouds. IEEE Transactions on Visualization and Computer Graphics, 17(6), 743-756.
21/10/2021 - Modélisation de la ventilation pulmonaire et calcul haute performance
Cet article a été écrit par Nina KESSLER et Samuel STEPHAN, à partir des présentations de Céline GRANDMONT et Hugo LECLERC du 21 Octobre 2021.
Les poumons permettent l’oxygénation du sang et l’évacuation du dioxyde de carbone produit par le corps. Pour réaliser ceci, le tissu pulmonaire possède une structure particulière, en forme d’arbre, qui permet à l’air d’aller de la trachée jusqu’aux alvéoles pulmonaires. Cet arbre compte en moyenne pour un poumon humain 23 générations de bronches de plus en plus petites. Si l’on peut respirer sans effort au repos, c’est grâce à la différence de pression entre les alvéoles et l’air ambiant, ainsi qu’à l’élasticité des tissus. Cependant, certaines pathologies peuvent interférer avec ce processus, comme l’asthme qui fait diminuer le diamètre des bronches, et réduit les capacités respiratoires. Les particules de poussière ou la pollution peuvent aussi avoir des conséquences sur la respiration. Afin de mieux comprendre le comportement du système pulmonaire et d’apporter des outils d’analyse dans les cas pathologiques, des modélisations mathématiques ont été proposées.
</em>")
Modélisation d'un arbre bronchique à l'aide d'un arbre dyadique (Source : [1])
Les poumons peuvent être modélisés comme un arbre constitué de N = 23 générations de bronches, dont chaque branche représente une bronche avec en dernière génération, des alvéoles representées par des masses séparées de ressorts. En première approximation, l’écoulement de l’air dans chaque bronche est uniquement caractérisé par un paramètre, la résistance R. Le débit Q est alors directement relié à la différence de pression à l’entrée et la sortie de la bronche ∆P par la relation ∆P = RQ. Le transport de l’air peut donc être modélisé mathématiquement grâce à un arbre composé de 2N résistances. La résistance associée aux bronches de la i-ème génération est de la forme Ri = Ri−1/β3 = R0/β3iavec β = 0.85. Donc, au niveau des alvéoles, puisque le flux est égal à Q23 = Q0/223, la différence de pression totale est égale à R23Q23 = R0Q0/(2β3)23 = (1.63/2)23R0Q0. Il est possible ensuite de déterminer le mouvement des alvéoles sous l’effet de la pression. La position ui(t) de la i-ième alvéole satisfait l’équation différentielle :
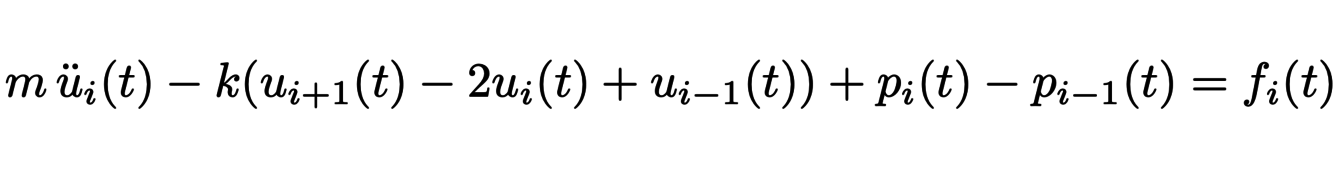
où le terme de pression
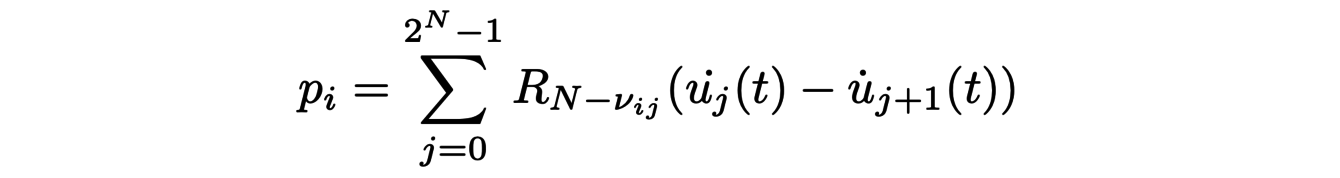
tient compte du couplage par l’arbre bronchique. Il peut être implémenté numériquement et comparé aux données expérimentales issues de l’imagerie dynamique de poumons. Ces données permettent de déterminer les paramètres du modèle, tester ses limites pour ensuite l’améliorer. Certaines limites sont dues aux conditions aux bords, c’est-à-dire, à la manière dont intéragissent l’arbre bronchique et l’air à son entrée. Mais, d’autres sont pratiques comme nous le verrons par la suite du fait du coût de calcul des simulations numériques.
Le modèle précédent a notamment été utilisé pour étudier des traitements respiratoires à base d’Héliox. L’Héliox est un mélange d’hélium et d’oxygène qui permettrait en effet de faciliter la respiration de personnes atteintes de pathologies pulmonaires. C’est un gaz moins dense, mais plus visqueux que l’air. La résistance au sein de l’arbre bronchique en est globalement réduite, et il en résulte que l’Heliox possède un régime laminaire lorsqu’il traverse un tuyau avec un faible débit. Ce gaz permet donc de réduire l’effort à fournir pour pour respirer. Cependant, lorsque le débit de gaz devient important, les bénéfices du produit sont considérablement réduits du fait de sa viscosité. En proposant une description de la dynamique globale de la ventilation, le modèle permet une analyse plus fine de son impact sur la respiration et permet de déterminer dans quels cas il est réellement bénéfique de l’utiliser.

Segmentation pulmonaire
L’application des modèles décrits précédemment sur des cas concrets nécessite une description plus précise de l’écoulement dans les premières bronches et donc l’acquisition de données sur des patients. Celle-ci peut être réalisée à l’aide de la tomographie permettant à partir d’une séquence d’image 2D de reconstituer une image 3D. Il convient ensuite d’appliquer un algorithme de segmentation afin de créer un maillage volumique de l’arbre bronchique. Cependant, les algorithmes de base permettant de reconstituer l’image d’une tomographie ne sont pas adaptés. En effet, les mouvements des organes dans la paroi toracique rendent l’acquisition des données bruitées. Une méthode de ségmentation récemment proposée consiste à partir d’une petite sphère contenue dans une zone de l’arbre puis à la faire progressivement grossir tout en minimisant à chaque instant sa surface totale.
Pour ce problème mais aussi pour beaucoup d’autres en mathématiques, la quantité de données à manipuler peut être très grande générant ainsi des temps d’exécution d’algorithme que l’on aimerait éviter. Pour réduire ces temps d’exécution, il est nécessaire de gérer plus finement les calculs effectués par les processeurs et les accès la mémoire RAM. L’utilisation optimale d’un processeur passe par la parallélisation des calculs qu’on lui donne à effectuer. Il peut être ainsi utile de vectoriser les calculs, c’est à dire permettre au processeur d’effectuer des opérations de manière simultanées sur des données voisines. Il est parfois également nécessaire de redéfinir les méthode numériques elles-mêmes pour tirer partie des nouvelles perfomances des outils de calculs. Ainsi, il est possible de créer des méthodes numériques très précises en utilisant le calcul symbolique. Ce méthodes requièrent potentiellement plus de calculs mais moins de communication avec la mémoire.
L’exemple des tissus pulmonaires illustre parfaitement les différentes étapes nécessaires pour l’étude de phénomènes physiologiques complexes. Même en effectuant beaucoup d’approximations sur la mécanique et la géométrie, cette démarche permet d’établir des modèles simplifiés qui permettent d’expliquer certaines données pour ensuite éventuellement orienter certaines études thérapeutiques. Ce travail met donc en jeu des compétences multiples allant de l’analyse des modèles jusqu’à une maitrise approfondie des outils informatiques pour accélérer les simulations numériques des modèles.
Références:
[1] Grandmont, C., Maury, B., & Meunier, N. (2006). A viscoelastic model with non-local damping application to the human lungs. ESAIM: Mathematical Modelling and Numerical Analysis, 40(1), 201-224.
07/10/2021 - Turbulence, aéronautique et dynamique fluide-particule
Cet article a été écrit par Raphaël COLIN et Thomas LUTZ-WENTZEL, à partir des présentations de Abderahmane MAROUF et Markus UHLMANN du 7 Octobre 2021.
</em>")
Simulation de turbulence autour d'une aile d'avion avec la méthode RANS (Source : [1])
Les expériences d’Osborne Reynolds (1883) ont montré l’existence de deux régimes d’écoulement d’un fluide : laminaire et turbulent. En faisant s’écouler un fluide dans une conduite cylindrique à un débit contrôlé, il a remarqué un changement du comportement de l’écoulement à mesure que le débit augmente. Le fluide passe d’un état régulier à un état désordonné, qui correspondent respectivement aux régimes laminaire et turbulent.
Le phénomène de turbulence désigne en fait l’état d’un liquide ou d’un gaz au sein duquel la vitesse présente en tout point un caractère tourbillonnaire. Ces tourbillons, présents à différentes échelles de longueurs, et ce jusqu’à l’échelle microscopique, voient leur taille, leur orientation ainsi que leur localisation changer constamment dans le temps.
Reynolds a introduit, à l’issue de ses expériences, le nombre de Reynolds :
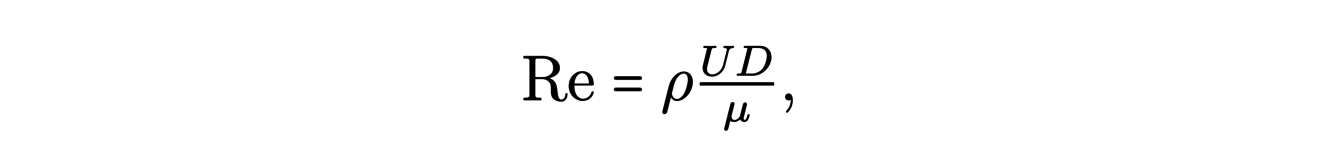
où ρ est la masse volumique du fluide, U sa vitesse caractéristique, μ son coefficient de viscosité et D la longueur de référence (par exemple le diamètre du cylindre dans l’expérience de Reynolds). Ce nombre caractérise le comportement de notre fluide dans un domaine donné. Une grande valeur de Re est synonyme d’un comportement turbulent.
Les équations de Navier-Stokes décrivent le comportement des fluides incompressibles. Elles s’écrivent :
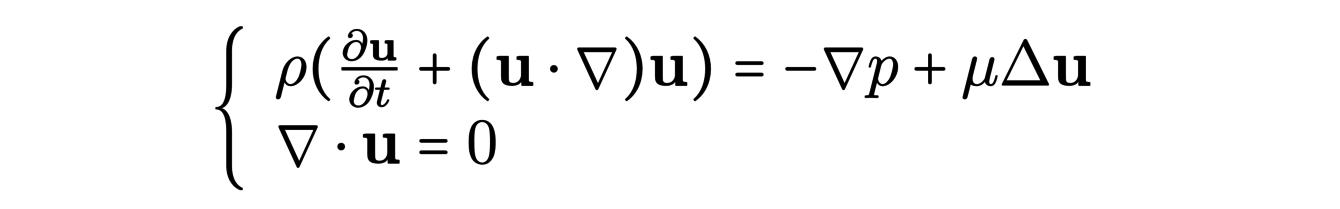
La résolution numérique de ces équations dans le cas d’un fluide turbulent est difficile. En effet, pour ce faire, on doit discrétiser l’espace en utilisant un maillage spatial. On obtient alors des cellules (des petits volumes) sur lesquelles la vitesse et la pression sont constantes et évoluent au cours du temps. Une bonne approximation nécessite de contrôler ce qui se passe à l’intérieur de ces cellules : on souhaite que le fluide y soit régulier. La présence de tourbillons à l’échelle microscopique nous pousse alors à considérer des maillages très fins, ce qui augmente considérablement le coût de calcul.
On dispose de diverses méthodes pour la résolution numérique, par exemple les méthodes DNS (direct numerical simulation) et RANS (Reynolds Averaged Navier-Stokes).
La DNS est la plus précise des deux, Elle consiste à résoudre directement les équations de Navier-Stokes en utilisant un maillage suffisamment fin pour capturer les plus petites structures tourbillonnaires. Elle a pour désavantage son coût en calcul qui peut la rendre inutilisable en pratique.
La méthode RANS (Reynolds Averaged Navier Stokes), quant à elle, se base sur une description statistique locale du la vitesse. Pour cela, on décompose la vitesse dans chaque cellule comme la somme d’une vitesse moyenne et d’un terme de perturbation :
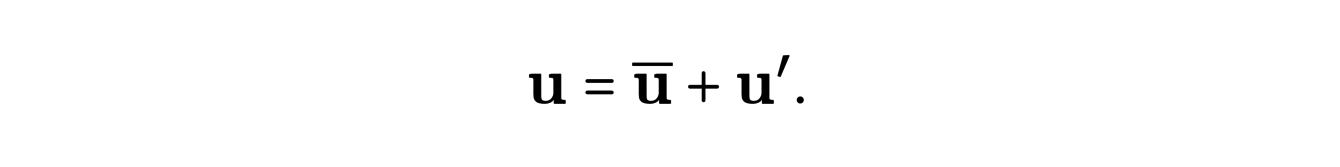
En insérant cette expression dans les équations et après simplifications, on obtient l’équation suivante :
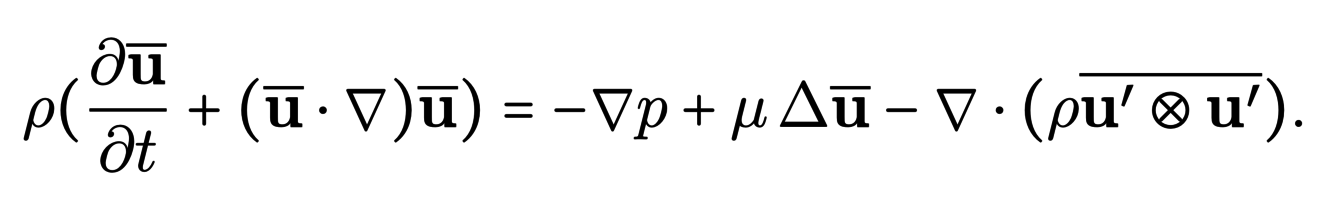
Le dernier terme de cette équation, appelé tenseur des contraintes de Reynolds, rend compte de l’effet des fluctuations autour de la vitesse moyenne. Les méthodes RANS modélise ce terme en utilisant des hypothèses de type viscosité de turbulence. Les modèles obtenus permettent l’utilisation de maillage plus grossier qui vont capturer la majorité des structures tourbillonnaires. Cette méthode est moins précise que la méthode DNS mais son coût de calcul est plus raisonnable.
Ces méthodes numériques sont utilisées dans de nombreuses applications. Par exemple, en aéronautique, le phénomène de couche limite donne lieu à un écoulement turbulent de l’air sur la surface des ailes des avions. Cela peut provoquer une baisse des performances aérodynamiques voire même une cassure de l’aile via le phénomène de résonance. Les techniques de bio-morphing cherchent à développer des ailes adaptables dans le temps, et ce, afin de diminuer l’impact des turbulences sur celles-ci. Par exemple, via une variation contrôlée de la température des matériaux constituants l’aile, on peut modifier leur rigidité pendant le vol. Cela permet leur déformation en une forme adaptée à la phase de vol considérée.
Il est également intéressant d’étudier le comportement de particules dans des fluides turbulents, étant donné que ce type de systèmes est omniprésent dans la nature (nuages, transport de sédiments, etc.) ou les systèmes industriels (fours solaires). Fluides et particules interagissent alors de manière complexe puisque la turbulence influe sur la dynamique des particules et les particules peuvent elles-mêmes modifier les propriétés turbulentes du fluide.
</em>")
Description particulaire dans un écoulement turbulent (Source : [2])
La distribution spatiale des particules est par exemple modifiée par la force centrifuge due aux structures tourbillonnaires du fluide turbulent, mais également par l’effet de sillage (les particules qui en suivent d’autres sont moins ralenties par le fluide, ce qui a pour effet de grouper les particules). Les fluides turbulents ont également une influence sur la vitesse terminale des particules (vitesse atteinte lorsque la résistance du fluide réduit l’accélération de la particule à zéro, sa vitesse n’évolue donc plus), par exemple, certaines particules vont être attirées par certaines parties des structures tourbillonnaires, ce qui a un effet sur leur vitesse terminale. L’effet des particules sur la turbulence n’est pas bien compris, et nécessite l’utilisation de modélisations différentes pour les particules et le fluide, qu’il faut ensuite réussir à combiner. Les particules peuvent réduire ou au contraire amplifier le comportement turbulent du fluide (augmenter la vitesse des tourbillons ou bien les dissiper).
Pour simuler de tels systèmes fluides-particules, il y a plusieurs interactions à calculer : les effets du fluide sur les particules et des particules sur le fluide, et les interactions particule-particule. Pour les interactions fluides-particules, on peut utiliser la méthode des frontières immergées, où en plus du maillage qui est un échantillonnage de l’espace, la surface des particules est échantillonnée en différents points sur lesquels les forces qui s’appliquent sont calculées. Le mouvement des particules peut être calculé avec une version discrète des équations de Newton. D’autres méthodes existent également, notamment des méthodes qui utilisent un maillage de l’espace adaptatif (plus fin autour des particules et plus grossier ailleurs), pour réduire le coût en calculs. Les calculs d’interactions entre particules nécessitent quant à eux des méthodes plus classiques de détection de collisions et d’application des forces.
On a pu voir que les méthodes DNS sont très coûteuses en termes de ressources de calcul, et il convient de s’intéresser aux performances de telles simulations. Il est possible de diviser la grille régulière sur laquelle on travaille en un certain nombre de sous-domaines, chacun peut être associé à un processeur, afin de traiter les calculs en parallèle. Ainsi, il peut se poser de nouveaux problèmes, par exemple sur le traitement des particules lorsqu’elles voyagent d’un sous-domaine à un autre, et l’équilibrage de la charge de calcul (en effet, que faire si la majorité des particules sont dans un seul sous-domaine ?).
La turbulence est un phénomène qui intervient dans de nombreux domaines comme en aéronau- tique ou encore lors de la conception de fours solaire. Le développement de formes tourbillonnaires à petites échelles nécessite le développement de méthodes numériques performantes avec des optimisations des capacités de calculs ou en utilisant des modèles simplifiés.
Références:
[1] Marouf, A., Simiriotis, N., Tô, J.-B., Rouchon, J.-F., Braza, M., Hoarau, Y. (2019). Morphing for smart wing design through RNAS/LES methods . ERCOFTAC Bulletin.
[2] Chouippe, A., Uhlmann, M. (2019). On the influence of forced homogeneous-isotropic turbulence on the settling and clustering of finite-size particles. Acta Mechanica, 230(2), 387-412.
23/09/2021 - Géométrie symplectique et astrophysique
Cet article a été écrit par Robin RIEGEL et Nicolas STUTZ , à partir des présentations de Rodrigo IBATA et Alexandru OANCEA du 23 Septembre 2021.
</em>")
Courants stellaires obtenus à partir du satellite Gaia (Source : [1])
La matière noire compose environ 25% de l’Univers mais est encore très mystérieuse. Le modèle standard de cosmologie dénommé ΛCDM fournit une théorie permettant de rendre compte des interactions de la matière noire avec les structures de l’Univers.
Pour pouvoir valider ce modèle, une possibilité est d’étudier les résidus d’amas d’étoiles de faibles masses orbitant autour de la Voie Lactée, appelés courants stellaires, interagissant avec la matière noire dont les trajectoires ont été enregistrées par le satellite Gaïa. Mais cela s’avère très difficile. En effet, le modèle ΛCDM permet de prédire les accélérations de ces étoiles mais il est impossible de mesurer ces accélérations en un temps convenable. Il faudrait des milliers, voire des millions d’années pour de telles structures avec nos instruments actuels.
Une autre approche est alors envisagée, où nous verrons que les outils de géométrie symplectique jouent un rôle déterminant.
Au lieu d’utiliser les données pour valider un modèle théorique, les astrophysiciens essaient de construire un modèle à partir des données. Plus précisément, il s’agit de déterminer la fonction Hamiltonienne H(q, p), ou énergie du système, fonction des positions q = (q1, . . . , qN ) et impulsions p = (p1, . . . , pN ). La dyamique hamiltonienne associée est le système différentiel suivant :
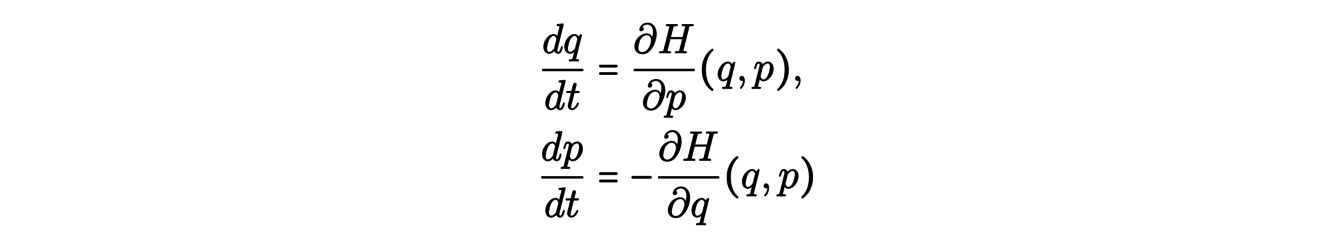
Tel quel, ce système est trop compliqué pour apprendre H à partir des données. Cependant, les outils de géométrie symplectique permettent de simplifier l’étude de ce système en l’exprimant dans de nouvelles coordonnées. Le but est de trouver des coordonnées (P(p,q),Q(p,q)) permettant d’obtenir un système plus simple à résoudre et donnant plus d’informations sur le système. Les flots de ce système hamiltonien préservent la 2-forme symplectique et donc certaines propriétés associées telles que le volume par exemple. Ainsi, les changements de coordonnées de la forme (P, Q) = φ(p, q) où φ est un flot du système sont des transformations privilégiées. Un tel changement de coordonnées est appelé transformation canonique.
Les coordonnées naturelles à chercher sont les coordonnées action-angle (θ(p,q),J(p,q)) solutions d’un système hamiltonien :
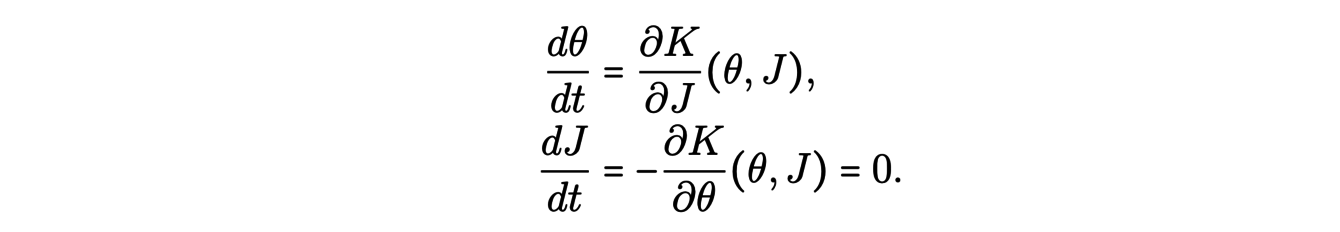

Illustration de la méthode utilisée dans [2] pour l'apprentissage des coordonnées action-angle
En effet pour ce système de coordonnées, le hamiltonien K(θ,J) ne dépend alors pas de θ et l’intégration est alors plus simple. De plus, J est constant le long des trajectoires de chaque astre.
Ce système de coordonnées donne donc beaucoup d’informations : il permet notamment de pouvoir clairement identifier les objets considérés et finalement de déduire le champs d’accélération.
Comment alors trouver ces coordonnées action-angle à partir des données ? Jacobi a introduit il y a environ 200 ans les fonctions dites génératrices S(q,P) d’une transformation canonique (P, Q) = φ(p, q).
Cette fonction vérifie les relations
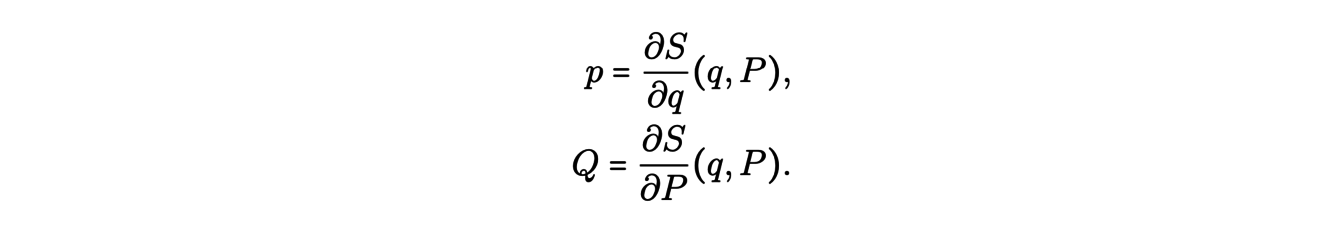
Ces conditions viennent du fait que la forme symplectique s’annule sur l’ensemble des
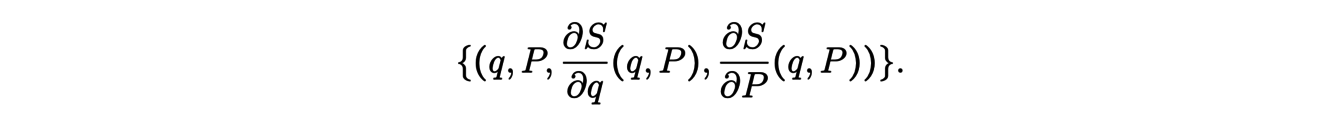
Cette fonction génératrice permet ainsi de garantir que le changement de coordonnées préserve la structure symplectique. Pour déterminer les coordonnées (θ,J) à partir des données, il est possible d’utiliser une méthode d’apprentissage profond à base de réseaux de neurones qui calcule la fonction génératrice en imposant que J soit invariant sur chaque trajectoire.
Ainsi, en partant des observations des courants stellaires et en étudiant le système hamiltonien on peut déterminer des coordonnées (θ,J) et donc trouver l’hamiltonien de ce système. Ce dernier contient toute la physique du système et en particulier l’effet de la matière noire sur la dynamique des étoiles. C’est pourquoi l’étude des courants stellaires est très prometteuse pour sonder la matière noire en confrontant les champs d’accélération calculés avec ceux prévus par le modèle ΛCDM.
Références :
[1] Ibata, R., Malhan, K., Martin, N., Aubert, D., Famaey, B., Bianchini, P., Monari, G., Siebert, A., Thomas, G.F., Bellazzini, M., Bonifacio, P., Renaud, F. (2021). Charting the Galactic Acceleration Field. I. A Search for Stellar Streams with Gaia DR2 and EDR3 with Follow-up from ESPaDOnS and UVES. The Astrophysical Journal, 914(2), 123.
[2] Ibata, R., Diakogiannis, F. I., Famaey, B., & Monari, G. (2021). The ACTIONFINDER: An unsupervised deep learning algorithm for calculating actions and the acceleration field from a set of orbit segments. The Astrophysical Journal, 915(1), 5.
09/09/2021 - Géométrie différentielle discrète
Cet article a été écrit par Philippe FUCHS et Claire SCHNOEBELEN, à partir des présentations de Mathieu DESBRUN et Franck HETROY-WHEELER du 9 Septembre 2021.
Il est fréquent qu’un objet de la vie réelle soit modélisé par une surface pour les besoins d’animations ou de simulations 3D. Pour pouvoir être manipulés par des ordinateurs, dont les capacités de calcul et de stockage sont limitées, les contours de cet objet sont approchés par un nombre fini de polygones juxtaposés, dont l’ensemble est appelé "maillage". C’est cette représentation, discrète, de la surface de l’objet qui est ensuite utilisée numériquement.
</em>")
Courbure moyenne sur le maillage d'un cheval (Source : [1])
Pour analyser et manipuler ces surfaces, il est intéressant de les approcher du point de vue de la géométrie différentielle. Celle-ci permet, notamment à travers les concepts de courbures, de caractériser les surfaces régulières. Pour exploiter ces outils sur nos surfaces polygonales, il est toutefois nécessaire d’en étendre préalablement les définitions. Considérons par exemple la courbure, une notion centrale dans l’étude des surfaces. Telle qu’elle est définie sur une surface lisse, elle n’a pas de sens sur une surface planaire par morceaux. Comme nous le verrons ensuite, il est toutefois possible de redéfinir les notions de courbures à l’aide de la formule de Gauss-Bonnet et de l’opérateur de Laplace-Beltrami discret.
Voyons à présent comment la courbure est définie pour une surface régulière. Sur une telle surface, chaque point x est contenu dans un voisinage V paramétré par une certaine application lisse X à valeurs d’un ouvert U du plan dans V. L’ensemble des paramétrisations locales X décrit un plongement de la suface dans R3. Les dérivées premières de X déterminent ce que l’on appelle la première forme fondamentale, une forme quadratique à partir de laquelle on définit une distance sur la surface. Les dérivées secondes de X déterminent quant à elle l’opérateur de forme de la surface, à partir duquel sont définies les différentes notions de courbure. La courbure gaussienne et la courbure moyenne en x sont ainsi définies comme étant respectivement le déterminant et la moitié de la trace de cet opérateur.
De ces deux notions de courbures, seule l’une est indépendante du plongement : la courbure moyenne. La courbure gaussienne peut en fait s’exprimer comme fonction des coefficients de la première forme fondamentale et de ses dérivées qui, contrairement à l’opérateur de forme, ne dépendent pas du plongement de la surface dans R3. Pour cette raison, on dit de la courbure gaussienne qu’elle est intrinsèque et de la courbure moyenne qu’elle est extrinsèque. De manière générale, on dit qu’une quantité est extrinsèque si elle dépend du plongement de la surface dans R3, autrement dit s’il est nécessaire pour la mesurer de considérer la position de la surface dans l’espace. A l’inverse, les quantités intrinsèques sont celles que l’on peut définir sur la surface en temps qu’ensemble muni de ses propres propriétés, sans avoir recours à l’espace ambiant, et qui ne dépendent pas de la façon dont on observe la surface de l’extérieur. Le plan et le cylindre, ont par exemple la même première forme fondamentale, et donc la même courbure gaussienne, mais pas la même courbure moyenne. Cela illustre le fait qu’il s’agit de deux surfaces localement isométriques plongées différemment dans R3.
Voyons maintenant comment définir la courbure sur nos surfaces polygonales. Il n’est pas possible d’y définir un opérateur de forme comme cela a été fait sur les surfaces régulières. Pour étendre les deux précédentes notions de courbure, il est nécessaire de les approcher différemment. On sait par exemple que la courbure gaussienne K intervient dans la formule de Gauss-Bonnet :
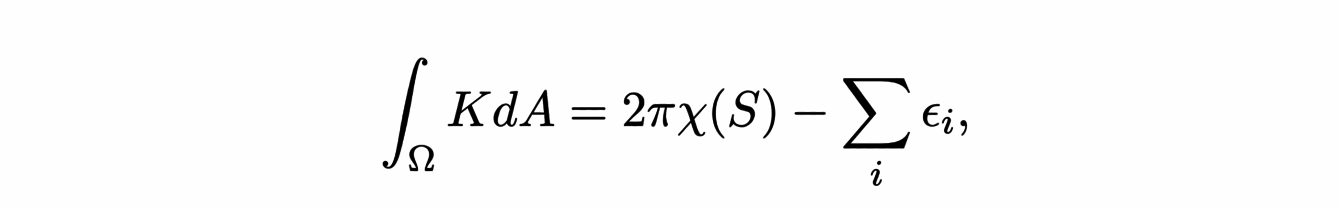
où χ(S) représente la caractéristique d’Euler de la surface et les εi les angles extérieurs du bord du domaine Ω . En choisissant un voisinage Ω de x dans notre surface polygonale, on peut définir la courbure gaussienne en x comme étant
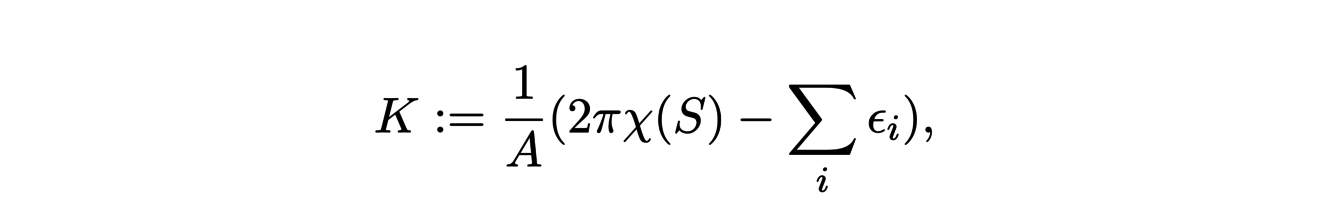
où A est l'aire deΩ. De la même manière, on peut étendre la définition de courbure moyenne en partant de l’égalité suivante :
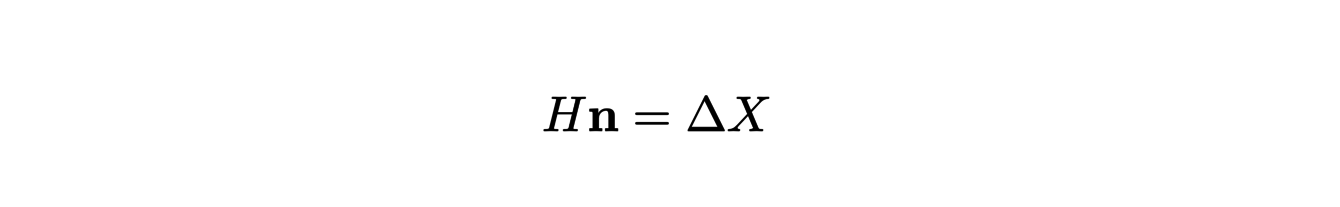
où ∆ représente l’opérateur de Laplace sur la surface. Il est possible de donner un équivalent à cet opérateur dans le cas des surfaces polygonales : l’opérateur de Laplace-Beltrami discret. La formule précédente, appliquée à ce nouvel opérateur, permet ainsi de définir la courbure moyenne de notre surface en x.
Le procédé qui consiste à exploiter certaines propriétés d’une notion utilisée en géométrie différentielle afin d’en proposer une définition dans le cas discret peut être utilisé pour d’autres généralisations. Par exemple, pour débruiter une surface issue d’un scan, on voudrait appliquer une méthode similaire à la diffusion non-linéaire utilisée sur les surfaces régulières, donnée par
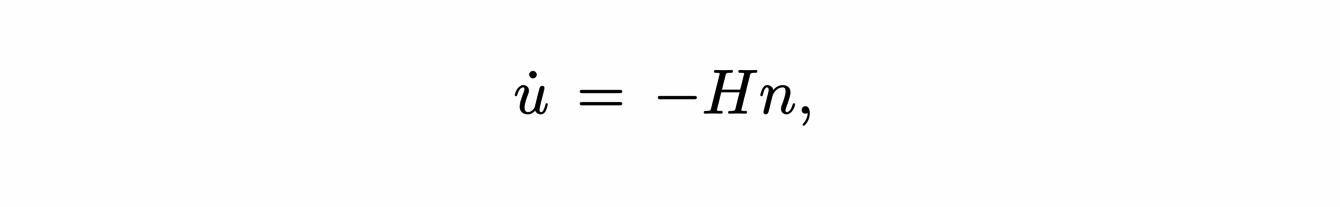
où n est un vecteur normal à la surface. L’équation précédente ne peut toutefois pas s’appliquer telle quelle aux surfaces polygonales. En revenant à l’origine de cette équation, on s’aperçoit que le mouvement u de la surface qu’elle décrit est en fait celui qui minimise le plus rapidement l’aire. Ayant constaté cela, il est aisé, en utilisant le gradient de l’aire, de mettre au point une méthode pour débruiter les surfaces polygonales qui, quand le maillage devient de plus en plus fin et tend vers une surface régulière, revient à appliquer la diffusion non-linéaire qu’on s’est donnée au départ.
</em>")
Lignes de champ sur une surface avec singularités aux points rouges et verts (Source : [2])
L’extension des concepts de géométrie différentielle sur les surfaces polygonales trouve beaucoup d’autres applications pratiques. Supposons par exemple que l’on veuille, dans le cadre d’un film d’animation, dessiner le pelage d’un animal. On modélise l’animal en question par une surface polygonale et son pelage par un champ de vecteurs sur cette surface. Pour que le rendu soit réaliste, on voudrait créer un champ lisse presque partout et en déterminer à l’avance les singularités.
La façon de procéder la plus répandue exploite le transport parallèle. Cette notion, d’abord définie sur les surfaces régulières, peut facilement être généralisée aux surfaces planaires par morceaux. Sur un plan, le transport parallèle relatif à la connexion de Levi-Civita prend la forme très simple d’une translation. Pour le définir sur la surface toute entière, il suffit donc de déterminer la façon de transporter un vecteur v d’une face P à l’une de ses voisines P'. Il s’agit pour cela de considérer ces deux faces comme étant deux morceaux d’un plan que l’on aurait plié. Déplions-le un instant : les deux faces font maintenant partie d’un même plan, sur lequel on peut transporter v en le translatant d’une face à l’autre. Replions nos deux faces. Le vecteur obtenu après translation de v est un vecteur tangent à P' et c’est celui-ci que l’on définit comme étant le transport parallèle de v de P à P’.
En définissant ainsi le transport parallèle, on se heurte à la notion d’holonomie. Considérons un sommet de notre surface polygonale et l’ensemble des faces qui lui sont attachées. En transportant un vecteur d’une face à l’autre avec le procédé décrit ci-dessus, il se peut que le vecteur obtenu après avoir fait un tour complet du sommet en passant de face en face ne soit pas colinéaire au vecteur d’origine. Ce sera en fait le cas dès que ces faces ne sont pas toutes coplanaires. Afin d’éviter de genre de phénomène, on ajoute une étape à ce qui précède. Pour chaque paire de faces, on compose la translation sur les faces dépliées avec une rotation, de sorte que le transport parallèle d’un vecteur autour d’un sommet coïncide avec le vecteur d’origine. Il est possible de définir ces rotations sur toute la surface en s’assurant qu’autour de presque tous les sommets le transport d’un vecteur coïncide avec lui-même : l’ensemble des angles de ces rotations sont solutions d’un grand système linéaire. Avec cette méthode, il est aussi possible de définir par avance les sommets autour desquels l’holonomie ne sera pas nulle. En procédant de cette manière, on peut, à partir d’un seul vecteur transporté sur toutes les faces, construire un champ de vecteur lisse partout sur la surface sauf en quelques points prédéterminés.
Les deux exemples précédents illustrent l’intérêt que revêt l’extension des outils de la géométrie différentielle aux surfaces polygonales : l’application des outils de la géométrie différentielle discrète a ici permis de construire deux méthodes efficaces et élégantes pour résoudre des problèmes concrets d’imagerie 3D.
Références :
[1] Meyer, M., Desbrun, M., Schröder, P., & Barr, A. H. (2003). Discrete differential-geometry operators for triangulated 2-manifolds. In Visualization and mathematics III (pp. 35-57). Springer, Berlin, Heidelberg.
[2] Crane, K., Desbrun, M., & Schröder, P. (2010, July). Trivial connections on discrete surfaces. In Computer Graphics Forum (Vol. 29, No. 5, pp. 1525-1533). Oxford, UK: Blackwell Publishing Ltd.